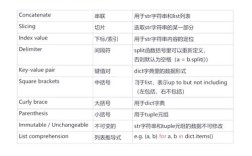
为什么会有编码问题?
DBF 文件(特别是 dBASE III 和 dBASE IV 格式)的一个设计缺陷是,它没有在文件头中明确存储字符编码信息,文件只记录了字符的“代码页”(Code Page),这是一个相对模糊的概念,或者干脆不记录。

(图片来源网络,侵删)
当你用 Python 读取 DBF 文件时,dbfread 库必须“猜测”或者由你“告诉”它应该使用哪种编码(如 gbk, utf-8, latin1 等)来解码字节,如果猜错了或者指定的编码不正确,读取出来的文本就会变成乱码( 这种形式)。
解决方案:在 Table 对象中指定编码
dbfread 提供了最直接的方式来解决编码问题:在创建 Table 对象时,通过 encoding 参数明确指定正确的编码。
语法
from dbfread import DBF
# 假设你的文件是 gbk 编码(非常常见于中国的 FoxPro, Visual FoxPro 等系统)
table = DBF('your_file.dbf', encoding='gbk')
for record in table:
print(record)
常见的编码值
'gbk'或'gb2312': 在中国大陆生成的 DBF 文件最常用的编码,如果你的文件来自中国的旧系统(如 FoxPro),这通常是首选。'utf-8': 国际标准编码,现代系统或跨平台生成的文件可能使用此编码。'latin1'(或'cp1252'): 这是一个“万能”但不太准确的编码,它将每个字节都映射到一个字符,不会抛出解码错误,但几乎肯定会产生乱码,只有在其他编码都失败时,才可以用它来“读取”原始字节,以便进一步分析。'cp936':gbk在 Windows 代码页中的名称,通常与'gbk'互换使用。- 其他: 你还可以使用 Python 支持的任何其他编码名称,如
'big5'(繁体中文),'shift_jis'(日文) 等。
如何确定正确的编码?
这是最困难的一步,如果你不确定文件的编码,可以尝试以下方法:
文件来源信息(最可靠)
- 询问提供者:直接问给你 DBF 文件的人或系统,这是什么编码?这是最简单、最准确的方法。
- 系统背景:如果文件来自中国的旧版 FoxPro、Visual FoxPro 或类似的管理系统,
gbk的可能性超过 99%,如果来自国际化的现代软件,则可能是utf-8。
试探法(Trial and Error)
如果无法获取来源信息,只能通过尝试来猜测。

(图片来源网络,侵删)
from dbfread import DBF
file_path = 'your_file.dbf'
encodings_to_try = ['gbk', 'utf-8', 'latin1']
for encoding in encodings_to_try:
print(f"\n--- 尝试编码: {encoding} ---")
try:
# 使用 ignore 错误处理,避免个别字符解码失败导致程序中断
table = DBF(file_path, encoding=encoding, load=True, ignore_missing_memofile=True)
# 打印第一条记录来检查
if len(table) > 0:
first_record = table[0]
print("成功读取!第一条记录的一个字段示例:")
# 找一个看起来像文本的字段来打印
for key, value in first_record.items():
if isinstance(value, str) and len(value) > 5:
print(f"字段 '{key}': {value}")
break # 只打印一个示例即可
# 如果没有长文本字段,直接打印整个记录
if not any(isinstance(v, str) and len(v) > 5 for v in first_record.values()):
print(first_record)
# 如果读取成功,就找到了正确的编码
break
except UnicodeDecodeError:
print(f"解码失败,编码 {encoding} 不正确。")
except Exception as e:
print(f"发生其他错误: {e}")
使用 chardet 库自动检测(有时不准确)
chardet 是一个流行的 Python 库,可以用来猜测文本的编码,对于 DBF 文件,你可以读取其内容的一部分来让 chardet 分析。
注意:这种方法不一定可靠,特别是对于短文本或混合内容的字段,但它可以作为一个辅助工具。
# 首先安装 chardet: pip install chardet
import chardet
from dbfread import DBF
file_path = 'your_file.dbf'
# 1. 先用 latin1 读取,因为它不会报错,可以拿到原始字节
try:
# raw_table 会以字节形式返回字符串值
raw_table = DBF(file_path, encoding='latin1', ignore_missing_memofile=True)
# 2. 收集一些样本文本
sample_text = ''
record_count = 0
for record in raw_table:
for value in record.values():
if isinstance(value, str) and len(value) > 10: # 找一些较长的文本
sample_text += value + ' '
record_count += 1
if record_count > 5: # 取前5个长文本字段就够了
break
if record_count > 5:
break
if sample_text:
# 3. 使用 chardet 检测
result = chardet.detect(sample_text.encode('latin1'))
confidence = result['confidence']
detected_encoding = result['encoding']
print(f"chardet 检测结果: 编码={detected_encoding}, 置信度={confidence:.2f}")
if confidence > 0.8: # 如果置信度很高,可以尝试使用
print(f"尝试使用检测到的编码: {detected_encoding}")
table = DBF(file_path, encoding=detected_encoding, ignore_missing_memofile=True)
for record in table[:1]: # 打印一条记录验证
print(record)
else:
print("未能找到足够长的文本样本进行检测。")
except Exception as e:
print(f"检测过程中出错: {e}")
完整示例与最佳实践
下面是一个结合了错误处理和编码试探的完整、健壮的示例。
from dbfread import DBF, DBFError
def read_dbf_with_encoding(file_path, encoding='gbk'):
"""
尝试用指定编码读取 DBF 文件。
"""
try:
print(f"正在尝试用 '{encoding}' 编码读取文件...")
table = DBF(file_path, encoding=encoding, ignore_missing_memofile=True)
# 为了验证,我们加载第一条记录
# load=True 会立即加载所有数据,对于小文件没问题
# 对于大文件,可以迭代,但这里为了快速验证
first_record = next(iter(table))
if first_record:
print(f"成功!使用编码 '{encoding}'。")
# 打印字段名和类型
print("字段信息:")
for field in table.field_names:
print(f" - {field}: {table.field_types[field]}")
print("\n第一条记录内容:")
print(first_record)
return table
else:
print("文件为空。")
return None
except UnicodeDecodeError:
print(f"错误:编码 '{encoding}' 不匹配,导致解码失败。")
return None
except DBFError as e:
print(f"DBF 文件错误: {e}")
return None
except Exception as e:
print(f"发生未知错误: {e}")
return None
# --- 主程序 ---
if __name__ == "__main__":
dbf_file = 'your_file.dbf' # 替换为你的文件路径
# 根据经验,按可能性从高到低排序
possible_encodings = ['gbk', 'utf-8', 'cp936', 'big5', 'latin1']
dbf_table = None
for enc in possible_encodings:
dbf_table = read_dbf_with_encoding(dbf_file, enc)
if dbf_table:
# 成功读取,退出循环
break
if not dbf_table:
print("\n所有尝试的编码均失败,请检查文件来源或尝试其他编码。")
else:
# 在这里进行你的正常数据处理
print("\n开始正常处理数据...")
record_count = 0
for record in dbf_table:
# 你的业务逻辑...
# print(record)
record_count += 1
if record_count > 3: # 示例:只处理前3条
break
print(f"成功处理了 {len(dbf_table)} 条记录。")
- 核心方法:在创建
DBF对象时,使用encoding参数指定编码,如DBF('file.dbf', encoding='gbk')。 - 常见编码:中文环境下的 DBF 文件,
'gbk'是最有可能的编码。 - 如何确定:
- 首选:询问文件来源。
- 次选:使用试探法,按常见编码顺序尝试。
- 辅助:使用
chardet库进行初步检测(结果仅供参考)。
- 健壮代码:将读取逻辑封装在函数中,并用
try-except捕获UnicodeDecodeError来优雅地处理编码错误。 ignore_missing_memofile:这是一个有用的参数,可以忽略.dbt(备注文件) 文件缺失的警告,让程序继续运行。

(图片来源网络,侵删)