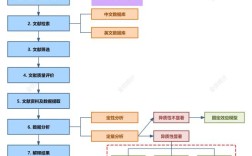
学习路线图 (Roadmap)
在学习之前,先建立一个清晰的框架,知道每一步该学什么,这样学习起来会更有方向感。

(图片来源网络,侵删)
-
基础准备阶段
- Python 基础: 掌握基本语法、数据类型、循环、函数、类等。
- 网络基础: 了解 HTTP/HTTPS 协议、URL、Request/Response、Headers、Cookie、Session 等基本概念。
-
入门爬虫阶段
- 核心库
requests: 学习如何发送 HTTP 请求、获取响应内容。 - 数据解析: 学习如何从 HTML 中提取数据。
BeautifulSoup: 简单易用,适合初学者。lxml: 性能强大,基于 XPath 和 CSS 选择器。
- 数据存储: 学习如何将爬取的数据保存到本地文件。
- 文本文件 (
.txt) - CSV 文件 (
.csv) - JSON 文件 (
.json)
- 文本文件 (
- 核心库
-
进阶爬虫阶段
- 动态网页爬取: 学习如何处理 JavaScript 渲染的页面。
Selenium: 模拟浏览器操作,是处理动态页面的利器。Playwright: 新一代自动化工具,比 Selenium 更快、更稳定。
- 数据解析进阶: 学习更高效、更精准的解析方法。
XPath: 在 XML/HTML 中查找信息的语言,功能强大。CSS Selector: 通过 CSS 选择器定位元素,简洁直观。
- 反爬虫与反反爬虫:
- 处理验证码: 手动识别、打码平台接口。
- 处理 IP 封禁: IP 代理池的搭建与使用。
- 处理动态请求: 分析 AJAX 请求,直接调用 API。
- 设置请求头: 模拟浏览器行为。
- 处理登录: Cookie、Session 的维持与模拟登录。
- 动态网页爬取: 学习如何处理 JavaScript 渲染的页面。
-
高级与框架阶段
 (图片来源网络,侵删)
(图片来源网络,侵删)- 爬虫框架
Scrapy: 学习使用功能强大的 Scrapy 框架进行大型、分布式爬虫项目开发。 - 数据存储进阶: 将数据存入数据库。
- 关系型数据库: MySQL, PostgreSQL (使用
SQLAlchemy或pymysql等库)。 - 非关系型数据库: MongoDB (非常适合存储爬虫的半结构化数据)。
- 关系型数据库: MySQL, PostgreSQL (使用
- 分布式爬虫: 了解 Scrapy-Redis 等框架,实现多机协同爬取。
- 爬虫框架
-
部署与运维
- 爬虫部署: 将爬虫部署到云服务器(如阿里云、腾讯云)上,实现 24/7 运行。
- 日志与监控: 记录爬虫运行状态,监控爬虫健康度。
- 任务调度: 使用
APScheduler等库定时执行爬取任务。
视频教程推荐
以下推荐的教程质量都比较高,涵盖了从入门到进阶的各个阶段。
Python 基础 (如果你是零基础)
- 黑马程序员 Python 基础教程
- 平台: Bilibili
- 特点: 国内最经典的 Python 入门教程之一,非常系统、详细,适合零基础小白,讲解通俗易懂。
- 链接: 在 Bilibili 搜索 “黑马程序员 Python” 即可找到。
入门爬虫 (核心内容)
-
Python 爬虫教程 - PYYaKee
- 平台: Bilibili
- 特点: 强烈推荐! 这位 UP 主的爬虫系列教程非常经典,从
requests到BeautifulSoup再到Selenium,讲解清晰,案例丰富,代码注释详细,是无数爬虫入门者的首选。 - 链接: Bilibili 搜索 “PYYaKee 爬虫”
-
莫烦 Python - Requests & BeautifulSoup 教程
 (图片来源网络,侵删)
(图片来源网络,侵删)- 平台: Bilibili, YouTube
- 特点: 莫烦老师的教程风格简洁、高效,代码驱动,适合有一定 Python 基础、想快速上手核心库的同学。
- 链接: Bilibili 搜索 “莫烦 python requests”
进阶与反爬
-
Python 爬虫教程 - 阿乐
- 平台: Bilibili
- 特点: PYYaKee 的进阶版,内容更深入,重点讲解了 Scrapy 框架 和 反反爬虫技术(如 IP 代理、验证码处理、动态渲染等),案例更具挑战性。
- 链接: Bilibili 搜索 “阿乐 python 爬虫”
-
Scrapy 框架官方文档 (有中文翻译)
- 平台: 官方文档 / GitHub
- 特点: 学习框架,官方文档是最好的资料,Scrapy 的文档非常详尽,包含教程、主题指南和 API 参考,配合视频食用效果更佳。
- 链接: Scrapy 官方文档中文版
综合实战
- “崔庆才”的《Python3 网络爬虫开发实战》配套视频
- 平台: Bilibili, 作者的博客
- 特点: 崔庆才是国内爬虫领域的专家,他的书是爬虫领域的“圣经”,Bilibili 上有他基于书籍内容录制的视频,内容非常全面和深入,覆盖了从静态到动态、从框架到部署的方方面面,适合系统学习和深入钻研。
- 链接: Bilibili 搜索 “崔庆才 爬虫实战”
核心知识点总结
在看视频的同时,要重点理解和掌握以下知识点:
| 模块 | 核心库/技术 | 主要用途 | 关键点 |
|---|---|---|---|
| 发送请求 | requests |
向服务器发起 HTTP 请求 | get(), post(), headers, cookies, params, data, proxies |
| 解析 HTML | BeautifulSoup |
将 HTML 文档解析为 Python 对象,方便查找 | find(), find_all(), select() (CSS选择器) |
lxml |
高性能的 HTML/XML 解析器 | etree, xpath() (XPath路径) |
|
| 处理动态页 | Selenium |
模拟真实浏览器,执行 JS 代码 | WebDriver, find_element(), implicitly_wait() |
Playwright |
新一代自动化工具,更现代 | Browser, Page, async/await 支持 |
|
| 数据存储 | csv, json |
存储为结构化文本文件 | csv.writer, json.dump/load |
pymysql, SQLAlchemy |
存入 MySQL 等关系型数据库 | SQL 语句, ORM (对象关系映射) | |
pymongo |
存入 MongoDB 等非关系型数据库 | insert_one(), find() |
|
| 爬虫框架 | Scrapy |
快速构建健壮、可扩展的爬虫项目 | Spider, Item Pipeline, Downloader Middleware, Scheduler |
| 反反爬 | 代理 IP | 绕过 IP 封禁 | requests.get(proxies=proxies) |
| 验证码识别 | 解决登录/提交障碍 | 超级鹰、打码平台 API | |
| Session/Cookie | 维持登录状态 | requests.Session() |
|
| AJAX 分析 | 直接获取数据接口 | 浏览器开发者工具 -> Network 标签 |
实战项目建议
光看不练假把式,通过项目来巩固所学知识是最好的方式。
-
入门级:
- 豆瓣 Top250 电影: 经典中的经典,练习
requests+BeautifulSoup,并将数据保存到 CSV 文件。 - 知乎热榜: 练习
requests获取 JSON 数据,了解 API 的调用。
- 豆瓣 Top250 电影: 经典中的经典,练习
-
进阶级:
- 招聘网站信息爬取 (如 Boss 直聘): 涉及到动态页面加载、模拟点击、处理反爬机制,是练习
Selenium的绝佳项目。 - 电商网站商品信息爬取 (如淘宝、京东): 难度较高,需要处理复杂的 JS 加载、动态价格、反爬验证码等,可以学习如何直接抓取其 API 接口。
- 招聘网站信息爬取 (如 Boss 直聘): 涉及到动态页面加载、模拟点击、处理反爬机制,是练习
-
高级/框架级:
- Scrapy 爬取新闻网站: 使用 Scrapy 框架爬取一个新闻网站的所有文章标题、内容和发布时间,并存储到 MongoDB 中。
- 知乎用户信息爬取: 爬取某个用户的关注列表、粉丝列表,并递归爬取其关注/粉丝的用户信息(注意遵守
robots.txt规则,不要过度爬取)。
学习建议
- 多动手,多写代码: 视频看懂了不代表会写了,一定要跟着敲,并尝试自己修改和扩展。
- 学会使用搜索引擎和官方文档: 遇到问题,先尝试自己搜索,学会看官方文档是程序员必备技能。
- 善用浏览器开发者工具: F12 是爬虫工程师的“眼睛”,可以用来分析网页结构、网络请求、定位元素。
- 保持耐心,遵守法律: 爬虫技术是中立的,但使用它必须遵守网站的
robots.txt协议,不要对服务器造成过大压力,更不要用于非法用途,做一个有道德的爬虫工程师!
祝你学习顺利,早日成为爬虫高手!