Java 程序员面试笔试宝典
前言
面试不仅是对知识的考察,更是对解决问题能力、逻辑思维、沟通能力和学习潜力的综合评估,本宝典将 Java 面试内容分为几个核心模块,每个模块都包含关键知识点、高频面试题、以及“面试官想听什么”的深度解析。

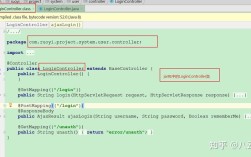
(图片来源网络,侵删)
第一部分:Java 基础
这是面试的敲门砖,也是最容易拉开差距的地方,基础不牢,地动山摇。
Java 语言特性
-
面试题:
- 和
equals()的区别是什么?hashCode()又有什么关系? final、finally、finalize的区别?String、StringBuilder、StringBuffer的区别?为什么String是不可变的?- 什么是自动装箱和拆箱?有什么需要注意的?
Object类有哪些方法?clone()是深拷贝还是浅拷贝?- 什么是 Java 的值传递?请解释一下。
- 和
-
核心知识点与解析:
- vs
equals():- 比较基本数据类型的值是否相等;比较引用数据类型的内存地址是否相等。
equals():Object类中的equals()默认也是比较地址(同 ),但很多类(如String、Integer、ArrayList)都重写了equals()方法,用于比较内容。hashCode()契约:如果两个对象equals()返回true,那么它们的hashCode()必须相等,反之不成立(哈希碰撞),这个契约是 Java 集合框架(特别是HashMap)正常工作的基础。
final、finally、finalize:final:关键字,可以修饰类(不可继承)、方法(不可重写)、变量(不可变)。finally:关键字,用于try-catch语句块中,无论是否发生异常,finally块中的代码一定会被执行(除非 JVM 退出),常用于资源释放(如关闭流)。finalize():方法,Object类的方法,在对象被 GC 回收前由 JVM 自动调用。不推荐使用,因为它执行时间不确定,且在 Java 9+ 中已被标记为deprecated。
String不可变性:- 优点:线程安全(可以被多个线程共享)、可以缓存哈希码(提高
HashMap等集合的性能)、常量池优化。 - 实现:
String内部使用final char[] value数组存储数据,且没有提供修改该数组的方法。
- 优点:线程安全(可以被多个线程共享)、可以缓存哈希码(提高
- 自动装箱/拆箱:
- 基本类型和其包装类型之间的自动转换。
int->Integer。 - 陷阱:会涉及对象创建,可能引发
NullPointerException(如Integer i = null; int j = i;),在-128到127范围内,会使用缓存对象,超出则创建新对象。
- 基本类型和其包装类型之间的自动转换。
- 值传递:
- Java 中只有值传递,对于基本类型,传递的是值的副本;对于引用类型,传递的是引用地址的副本,这意味着你可以修改引用指向对象的内容,但不能改变引用本身指向另一个对象。
- vs
集合框架
这是面试的重中之重,必须滚瓜烂熟。

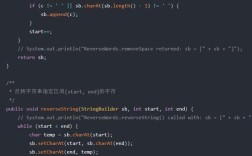
(图片来源网络,侵删)
-
面试题:
ArrayList和LinkedList的区别?底层实现是什么?增删改查的时间复杂度?HashMap的工作原理?put方法的详细流程?为什么是 2 的幂次容量?什么是哈希冲突?如何解决?ConcurrentHashMap是如何保证线程安全的?与Hashtable和Collections.synchronizedMap()的区别?HashSet是如何保证元素不重复的?底层是什么?ArrayList和Vector的区别?HashMap和TreeMap的区别?
-
核心知识点与解析:
ArrayListvsLinkedList:ArrayList:基于动态数组,查询快(O(1)),增删慢(可能需要移动元素,O(n)),有扩容机制(Arrays.copyOf)。LinkedList:基于双向链表,查询慢(O(n)),增删快(只需修改指针,O(1))。
HashMap工作原理:- 结构:数组 + 链表/红黑树,JDK 8 后,当链表长度超过 8 且数组长度超过 64 时,链表会转换为红黑树,查询效率从
O(n)提升到O(log n)。 put流程:- 计算
key的hash值。 - 通过
(n - 1) & hash定位到数组索引。 - 如果该位置为空,直接插入。
- 如果不为空,发生冲突,遍历链表/红黑树,
key已存在则覆盖,否则在末尾/树中插入。
- 计算
- 为什么是 2 的幂次? 这样
(n - 1) & hash的计算结果等价于hash % n,但位运算效率更高,能保证hash值的每一位都能参与到计算中,使分布更均匀。
- 结构:数组 + 链表/红黑树,JDK 8 后,当链表长度超过 8 且数组长度超过 64 时,链表会转换为红黑树,查询效率从
ConcurrentHashMap线程安全:- JDK 7:分段锁(
Segment),将数据分成多个段,每个段一把锁,并发度等于段数。 - JDK 8+:CAS +
synchronized,取消分段锁,采用数组+链表/红黑树结构,当发生哈希冲突时,使用synchronized锁住链表/红黑树的头节点,锁的粒度更细,并发性能更高。CAS操作用于保证volatile变量的原子性更新。
- JDK 7:分段锁(
HashSet:- 底层是一个
HashMap。HashSet的元素作为HashMap的key,value是一个静态的Object对象,利用了HashMap的key唯一性来保证元素的唯一性。
- 底层是一个
第二部分:Java 并发编程
衡量一个 Java 程序员水平高低的重要标尺。
-
面试题:
synchronized和ReentrantLock的区别?volatile关键字的作用?能保证原子性吗?ThreadLocal是什么?使用场景和原理是什么?会导致内存泄漏吗?CountDownLatch、CyclicBarrier、Semaphore的区别和使用场景?- 线程池的核心参数有哪些?工作流程是怎样的?拒绝策略有哪些?
- 什么是
AQS(AbstractQueuedSynchronizer)?它的工作原理是什么? - 什么是
CAS(Compare-And-Swap)?它的缺点是什么(ABA 问题)?
-
核心知识点与解析:
synchronizedvsReentrantLock:synchronized:JVM 层面的关键字,是非公平锁,不可中断,发生异常时锁会自动释放,使用简单。ReentrantLock:API 层面的类,支持公平/非公平锁(默认非公平),可中断(lockInterruptibly()),可设置超时(tryLock()),可精确唤醒(Condition),发生异常时不会自动释放,需要在finally中手动释放。
volatile:- 作用:保证可见性(一个线程修改后,其他线程立即可见)和禁止指令重排序。
- 不保证原子性:
volatile int count = 0; count++不是原子操作。
ThreadLocal:- 作用:为每个线程提供独立的变量副本,实现线程隔离。
- 原理:每个线程内部有一个
ThreadLocalMap,ThreadLocal作为key,变量作为value。 - 内存泄漏:由于
ThreadLocalMap的key是WeakReference,但value是StrongReference。ThreadLocal对象被回收,但线程(如线程池中的线程)一直存活,value就无法被回收,导致内存泄漏。解决方案:使用ThreadLocal后,务必在finally块中调用remove()方法。
- 线程池:
- 核心参数:
corePoolSize: 核心线程数。maximumPoolSize: 最大线程数。workQueue: 任务队列。keepAliveTime: 空闲线程存活时间。threadFactory: 创建线程的工厂。handler: 拒绝策略。
- 工作流程:
- 提交任务,如果核心线程数未满,创建核心线程执行。
- 如果核心线程数已满,任务放入队列。
- 如果队列已满,且未达到最大线程数,创建非核心线程执行。
- 如果队列已满且最大线程数已满,执行拒绝策略。
- 拒绝策略:
AbortPolicy(默认,抛异常)、CallerRunsPolicy(由提交任务的线程执行)、DiscardPolicy(直接丢弃)、DiscardOldestPolicy(丢弃队列中最老的任务)。
- 核心参数:
第三部分:JVM(Java 虚拟机)
深入理解 Java 代码的运行机制,是高级工程师的必备技能。
-
面试题:
- JVM 的内存结构是怎样的?哪些区域是线程私有的?
- 什么是 Java 的双亲委派模型?有什么好处?如何打破它?
- 常见的 JVM 调优参数有哪些?(如
-Xms,-Xmx,-XX:NewRatio) - 如何判断一个对象可以被回收?
GC Roots是什么? - 常见的垃圾回收器有哪些?它们的特点是什么?(Serial, Parallel, CMS, G1, ZGC)
- Minor GC 和 Full GC 的触发条件是什么?
-
核心知识点与解析:
- JVM 内存结构(运行时数据区):
- 线程私有:
- 虚拟机栈:存储方法执行时的信息(局部变量表、操作数栈、动态链接、方法出口)。栈溢出就是这里空间不足。
- 本地方法栈:为 native 方法服务。
- 程序计数器:记录当前线程执行的字节码行号。
- 线程共享:
- 堆:存放对象实例和数组,是 GC 的主要区域。
- 方法区:存储已被虚拟机加载的类信息、常量、静态变量等,JDK 8 后用 元空间 替代,使用本地内存。
- 线程私有:
- 双亲委派模型:
- 流程:类加载器收到加载请求时,先委派给父加载器,父加载器再委派给其父加载器,直到顶层的启动类加载器,如果父加载器无法完成加载,子加载器才会尝试自己加载。
- 好处:保证 Java 核心类库(如
java.lang.String)的唯一性,防止被篡改。 - 打破方式:重写
ClassLoader的loadClass()方法。
- 垃圾回收器:
- Serial GC:单线程,STW(Stop-The-World)时间长,适合客户端应用。
- Parallel GC (吞吐量优先):多线程,Serial GC 的并行版本,关注吞吐量,是 JDK 8 默认的 GC。
- CMS (Concurrent Mark Sweep):并发标记清除,关注 STW 时间,但会产生内存碎片,且并发失败时有 Full GC 风险,已被废弃。
- G1 (Garbage-First):面向服务端,将堆划分为多个 Region,可预测的停顿时间模型,是 JDK 9+ 默认的 GC。
- ZGC / Shenandoah:超低延迟 GC,STW 时间在毫秒甚至亚毫秒级别。
- JVM 内存结构(运行时数据区):
第四部分:框架与生态
现代 Java 开发离不开框架,Spring 是绕不开的核心。
Spring / Spring Boot
-
面试题:
- Spring IoC 和 AOP 的原理是什么?
- Bean 的生命周期是怎样的?
- Spring Bean 的作用域有哪些?
- 什么是循环依赖?Spring 是如何解决的?
- Spring MVC 的工作流程是怎样的?
- Spring Boot 的自动装配原理是什么?
@SpringBootApplication注解做了什么? - Spring 事务的传播机制有哪些?
-
核心知识点与解析:
- IoC (控制反转):将对象的创建和依赖的管理交给 Spring 容器,核心是容器和Bean。
- AOP (面向切面编程):在不修改源代码的情况下,对程序进行功能增强,核心是动态代理(JDK 动态代理、CGLIB 代理)。
- Bean 生命周期:
- 实例化(
Instantiation) - 属性填充(
Populate Properties) - 初始化(
Initialization,如@PostConstruct、InitializingBean) - 使用
- 销毁(
Destruction,如@PreDestroy、DisposableBean)
- 实例化(
- 循环依赖:指两个或多个 Bean 相互依赖,Spring 主要通过三级缓存来解决单例 Bean 的循环依赖问题,对于原型 Bean,无法解决。
- Spring Boot 自动装配:
- 核心:
@EnableAutoConfiguration注解。 - 原理:通过
spring.factories文件找到所有AutoConfiguration类,然后根据@Conditional系列注解(如@ConditionalOnClass、@ConditionalOnMissingBean)判断是否需要加载对应的 Bean 配置。 @SpringBootApplication:是@Configuration、@EnableAutoConfiguration、@ComponentScan的组合注解。
- 核心:
数据库与持久层
-
面试题:
- 索引的底层原理是什么?为什么 B+ 树比 B 树更适合做索引?
- 什么是事务?ACID 是什么?数据库的隔离级别有哪些?
- 什么是 SQL 注入?如何防止?
- 和 在 MyBatis 中的区别是什么?
- 乐观锁和悲观锁的实现方式?
- 数据库分库分表的基本思路是什么?
-
核心知识点与解析:
- B+ 树索引:
- B 树:所有节点都存储数据,查询不稳定。
- B+ 树:只有叶子节点存储数据,非叶子节点只存储索引,查询效率更稳定(所有查询都到叶子节点),范围查询更高效(叶子节点通过指针相连)。
- ACID 与隔离级别:
- ACID:原子性、一致性、隔离性、持久性。
- 隔离级别:读未提交、读已提交、可重复读、串行化,MySQL InnoDB 默认是可重复读,通过 MVCC(多版本并发控制)实现。
- SQL 注入:通过在输入中插入恶意 SQL 代码来执行非预期的命令。防止方式:使用预编译语句(
PreparedStatement),永远不要用字符串拼接 SQL。 - MyBatis vs :
- 预编译处理,替换为 ,防止 SQL 注入。
- 字符串替换,直接拼接 SQL,存在 SQL 注入风险,通常用于动态表名、列名。
- B+ 树索引:
第五部分:计算机基础与系统设计
这部分考察你的知识广度和解决复杂问题的能力。
算法与数据结构
-
面试题:
- 手写代码:反转链表、二叉树的前中后序遍历、快排、归并、二分查找。
- 什么是红黑树?它的特点是什么?
Top K问题有哪些解法?(堆、快排)LRU缓存如何实现?(LinkedHashMap或HashMap+双向链表)
-
核心知识点与解析:
- 务必亲手实现:链表、二叉树、排序算法是必考项,必须能熟练地手写出来。
- 时间/空间复杂度分析:写完代码后,要能清晰地分析出算法的时间和空间复杂度。
- 理解思想:不要只背代码,要理解每种数据结构和算法背后的思想(如分治、贪心、动态规划)。
系统设计
-
面试题:
- 设计一个短链接系统。
- 设计一个高并发的秒杀系统。
- 设计一个微信朋友圈/微博 Feed 流系统。
- 如何设计一个分布式 ID 生成器?
-
核心知识点与解析:
- 分析需求:明确系统的功能、性能(QPS、延迟)、可用性、扩展性要求。
- 拆分模块:将系统拆分为用户、服务、存储、缓存、消息队列等模块。
- 核心组件:
- 负载均衡:Nginx, F5。
- 缓存:Redis, Memcached,用于缓解数据库压力。
- 数据库:主从复制、分库分表。
- 消息队列:Kafka, RabbitMQ,用于削峰填谷、系统解耦。
- 服务化:微服务架构。
- 关注点:数据一致性(最终一致性)、高可用(冗余、故障转移)、可扩展性(水平/垂直扩展)。
第六部分:附加项
- Linux 基础:常用命令(
grep,awk,sed,top,netstat),日志分析。 - 网络基础:TCP/UDP 区别,三次握手/四次挥手,HTTP/HTTPS,DNS 解析过程。
- 设计模式:单例、工厂、策略、观察者等常用模式的应用场景。
- 项目经验:准备 1-2 个你最熟悉的项目,能清晰地讲出项目的背景、你的角色、技术选型、遇到的挑战以及如何解决的。
面试准备建议
- 系统复习:按照本宝典的框架,逐一过知识点,形成知识体系。
- 动手编码:LeetCode 刷题是王道,从简单题开始,逐步挑战中等题,重点掌握链表、二叉树、字符串、动态规划等。
- 准备项目:对自己做过的项目了如指掌,能用 STAR 法则(Situation, Task, Action, Result)清晰地描述。
- 模拟面试:找朋友或进行在线模拟面试,锻炼表达能力和临场反应。
- 准备提问:面试最后,一定要准备有深度的问题问面试官,这能体现你的思考和对公司的兴趣。“团队的技术栈是怎样的?”“新入职的员工会有什么样的培养机制?”“我入职后第一个接触的项目可能会是怎样的?”
祝你面试顺利,斩获心仪的 Offer!