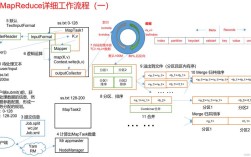
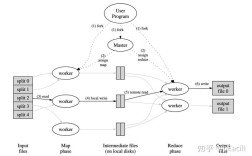
纯 Python 实现 MapReduce
这个实现将帮助我们理解 MapReduce 的核心思想:将一个大任务分解成许多小任务(Map),然后汇总这些小任务的结果(Reduce)。

核心概念
- Map (映射): 一个函数,它接收一个输入键值对
(key, value),并输出零个或多个中间键值对(key, value),这个阶段的核心是“分类”和“标记”。 - Shuffle (洗牌): MapReduce 框架自动执行的一个步骤,它收集所有 Map 阶段输出的中间键值对,并将具有相同
key的所有值分组在一起,形成一个列表,如果 Map 输出('apple', 1),('banana', 1),('apple', 1),Shuffle 后会变成{'apple': [1, 1], 'banana': [1]}。 - Reduce (规约): 一个函数,它接收一个
key和与该key相关的所有值的列表[value1, value2, ...],然后输出最终的零个或一个键值对(key, value),这个阶段的核心是“聚合”和“计算”。
实现场景:词频统计
这是 MapReduce 最经典的例子,假设我们有一个巨大的文本文件,我们想统计其中每个单词出现的总次数。
输入文件 input.txt:
hello world
hello python
map reduce is powerful
hello world目标输出:
hello: 3
python: 1
world: 2
map: 1
reduce: 1
is: 1
powerful: 1步骤 1: 编写 Mapper 函数
Mapper 的任务是读取每一行文本,将其拆分成单词,并为每个单词发出一个 (word, 1) 的键值对。

def mapper(line):
"""
Mapper 函数: 将每一行文本分割成单词,并为每个单词生成 (word, 1) 的键值对。
"""
# .lower() 使单词统计不区分大小写
words = line.lower().split()
for word in words:
# 发出键值对 (word, 1)
yield (word, 1)
步骤 2: 编写 Reducer 函数
Reducer 的任务是接收一个单词和它所有对应的 1(来自 Mapper),然后将这些 1 相加,得到单词的总次数。
def reducer(word, counts):
"""
Reducer 函数: 接收一个单词和它出现次数的列表,求和并输出最终结果。
"""
# counts 是一个列表,[1, 1, 1] 对应单词 'hello'
total_count = sum(counts)
# 输出最终结果 (word, total_count)
yield (word, total_count)
步骤 3: 模拟 MapReduce 执行流程
我们将手动编写一个脚本来模拟框架如何调用我们的 Mapper 和 Reducer。
import collections
def run_map_reduce(data_source, mapper_func, reducer_func):
"""
模拟 MapReduce 执行流程的主函数。
:param data_source: 可迭代的输入数据源 (文件行列表)。
:param mapper_func: 用户定义的 Mapper 函数。
:param reducer_func: 用户定义的 Reducer 函数。
"""
# --- 1. Map 阶段 ---
# 存储所有中间键值对
intermediate = []
for line in data_source:
# 调用 mapper,并收集其结果
# mapper_func(line) 返回一个生成器,我们将其展开
intermediate.extend(mapper_func(line))
# --- 2. Shuffle 阶段 ---
# 使用字典来对中间结果进行分组
# key: 单词, value: 包含所有 1 的列表
# collections.defaultdict(list) 非常适合这个场景
grouped_data = collections.defaultdict(list)
for key, value in intermediate:
grouped_data[key].append(value)
# --- 3. Reduce 阶段 ---
# 存储最终结果
final_results = []
for key in grouped_data:
# 调用 reducer,并收集其结果
# reducer_func(key, grouped_data[key]) 也返回一个生成器
final_results.extend(reducer_func(key, grouped_data[key]))
return final_results
# --- 主程序 ---
if __name__ == "__main__":
# 模拟从文件读取数据
input_data = [
"hello world",
"hello python",
"map reduce is powerful",
"hello world"
]
# 运行我们的 MapReduce
results = run_map_reduce(input_data, mapper, reducer)
# 打印结果 (MapReduce 框架会对 key 进行排序)
# 为了清晰,我们这里也排序一下
for word, count in sorted(results):
print(f"{word}: {count}")
运行结果
当你运行上面的 if __name__ == "__main__": 部分时,你会得到预期的输出:
hello: 3
is: 1
map: 1
powerful: 1
python: 1
reduce: 1
world: 2第二部分:使用 mrjob 库进行真实的 MapReduce
纯 Python 实现虽然有助于理解原理,但在处理真正的大数据集(GB 或 TB 级别的文件)时效率低下。mrjob 是一个由 Yelp 开源的 Python 库,它允许你在本地机器上编写和测试 MapReduce 作业,然后轻松地将其部署到 Amazon Elastic MapReduce (EMR) 或其他 Hadoop 兼容的集群上。

安装 mrjob
你需要安装它:
pip install mrjob
使用 mrjob 重写词频统计
mrjob 的美妙之处在于,你只需要写一个 Python 脚本,它就自动处理了所有的 Map、Shuffle、Reduce 步骤,以及数据的读写。
创建 wordcount_mrjob.py 文件:
from mrjob.job import MRJob
class MRWordCount(MRJob):
"""
一个继承自 MRJob 的类,用于定义 MapReduce 作业。
"""
def mapper(self, _, line):
"""
Mapper 函数。
mrjob 会自动将输入文件的每一行作为参数传递给这个函数。
"""
# yield (key, value)
for word in line.lower().split():
yield word, 1
def reducer(self, word, counts):
"""
Reducer 函数。
mrjob 会自动将所有具有相同 key 的 values 收集成一个 counts 列表,
然后传递给这个函数。
"""
# yield (key, final_value)
yield word, sum(counts)
if __name__ == '__main__':
# 这行代码会根据执行环境(本地、Hadoop、EMR)启动作业
MRWordCount.run()
运行 mrjob 脚本
在本地运行(使用一个文本文件作为输入)
创建一个 input.txt 文件,内容和我们之前的一样。
# 创建输入文件 echo -e "hello world\nhello python\nmap reduce is powerful\nhello world" > input.txt # 运行 mrjob 脚本 # -r local 表示在本地运行 python wordcount_mrjob.py -r local input.txt
输出:
"hello" 3
"is" 1
"map" 1
"powerful" 1
"python" 1
"reduce" 1
"world" 2注意,mrjob 的输出是制表符分隔的,这是 Hadoop 的标准格式。
运行在更大的文件上
mrjob 会自动处理多行输入,你可以直接把一个更大的文件传给它。
# 假设你有一个更大的文件 big_input.txt python wordcount_mrjob.py -r local big_input.txt
mrjob 的优势
- 简洁: 代码非常简洁,专注于业务逻辑,而非框架细节。
- 可扩展性: 只需更改
-r参数,就可以将作业从本地 (local) 部署到云端 (如-r emr)。 - 容错性: 真正的 MapReduce 框架(如 Hadoop)会处理节点故障、任务重试等复杂问题,
mrjob在部署到这些集群时能自动利用这些特性。
| 特性 | 纯 Python 实现 | mrjob 库 |
|---|---|---|
| 目的 | 学习 MapReduce 核心原理 | 解决实际问题,处理大数据 |
| 复杂度 | 需要手动模拟 Shuffle 等步骤 | 框架自动处理所有流程 |
| 适用场景 | 小数据集,教学,面试题 | 中大型数据集,本地开发和云端部署 |
| 可扩展性 | 差,难以处理分布式环境 | 优秀,一键切换到云端集群 |
对于初学者,强烈建议先理解纯 Python 的实现,因为它能让你深刻体会到 MapReduce 的精髓,在实际项目中,使用 mrjob 这样的库来提高效率和生产力。