核心概念澄清
我们需要明确几个术语:

(图片来源网络,侵删)
- UTF-8: 一种变长的字符编码方案,它可以用 1 到 4 个字节来表示一个 Unicode 字符。
- 英文字符(如 'A', '你')通常用 1 个字节。
- 汉字(如 '你', '好')通常用 3 个字节。
- 一些特殊符号(如 '😊')用 4 个字节。
- Unicode: 这是一个字符集,为世界上几乎所有的字符都分配了一个唯一的数字,这个数字就是代码点,代码点通常写作
U+4F60(代表 '你')。 - Java
char: Java 使用 UTF-16 编码来内部表示字符,一个char类型占用 2 个字节,可以表示大部分 Unicode 代码点(从U+0000到U+FFFF),对于超过U+FFFF的辅助字符(如 '😊'),需要用两个char来表示(一个代理对,surrogate pair)。
当我们将 UTF-8 转换为 "Unicode" 时,我们通常的目标是:
- 获取每个字符的代码点(一个
int值)。 - 获取一个标准的 Java
String对象,这个对象内部已经用 UTF-16 正确表示了所有字符。
使用 String 构造函数(最推荐、最简单)
这是最直接、最安全的方法,Java 的 String 类提供了可以直接用字节数组和字符集名称来构造字符串的构造函数。
示例代码
import java.nio.charset.StandardCharsets;
public class Utf8ToUnicodeExample {
public static void main(String[] args) {
// 1. 准备一个 UTF-8 编码的字节数组
// "你好" 的 UTF-8 编码是 E4 BD A0 E5 A5 BD
// "😊" 的 UTF-8 编码是 F0 9F 98 8A
byte[] utf8Bytes = "你好,世界!😊".getBytes(StandardCharsets.UTF_8);
System.out.println("原始 UTF-8 字节数组: " + bytesToHex(utf8Bytes));
// 输出: 原始 UTF-8 字节数组: e4 bd a0 e5 a5 bd ef bc 8c e4 b8 96 e7 95 8c ef bc 81 f0 9f 98 8a
// 2. 使用 String 构造函数将 UTF-8 字节数组解码为 String
// String 构造函数会自动处理 UTF-8 到 UTF-16 的转换
String decodedString = new String(utf8Bytes, StandardCharsets.UTF_8);
System.out.println("解码后的 String: " + decodedString);
// 输出: 解码后的 String: 你好,世界!😊
// 3. 遍历 String,获取每个字符的 Unicode 代码点
System.out.println("\n每个字符的 Unicode 代码点:");
for (int i = 0; i < decodedString.length(); i++) {
// charAt(i) 返回 UTF-16 编码的 char
// codePointAt(i) 返回真正的 Unicode 代码点,能正确处理代理对
int codePoint = decodedString.codePointAt(i);
// 如果是代理对,需要跳过下一个 char
if (Character.isSupplementaryCodePoint(codePoint)) {
i++; // 增加索引以跳过代理对的第二个单元
}
System.out.printf("字符: %c, 代码点: U+%04X (十进制: %d)\n",
(char) codePoint, codePoint, codePoint);
}
}
// 一个辅助方法,用于将字节数组打印为十六进制字符串,方便查看
private static String bytesToHex(byte[] bytes) {
StringBuilder sb = new StringBuilder();
for (byte b : bytes) {
sb.append(String.format("%02x ", b));
}
return sb.toString().trim();
}
}
输出结果
原始 UTF-8 字节数组: e4 bd a0 e5 a5 bd ef bc 8c e4 b8 96 e7 95 8c ef bc 81 f0 9f 98 8a
解码后的 String: 你好,世界!😊
每个字符的 Unicode 代码点:
字符: 你, 代码点: U+4F60 (十进制: 20320)
字符: 好, 代码点: U+597D (十进制: 22909)
字符: ,, 代码点: U+FF0C (十进制: 65292)
字符: 世, 代码点: U+4E16 (十进制: 19990)
字符: 界, 代码点: U+754C (十进制: 29992)
字符:!, 代码点: U+FF01 (十进制: 65281)
字符: 😊, 代码点: U+1F60A (十进制: 128522)为什么推荐这个方法?
- 简单:一行代码就能完成转换。
- 健壮:由 Java 标准库处理所有复杂的边界情况(如无效的 UTF-8 序列、代理对等)。
- 可读性高:代码意图非常明确。
使用 CharsetDecoder(更高级、更灵活)
如果你需要对解码过程进行更精细的控制(处理无效字符、解码到 CharBuffer 而不是直接生成 String),那么应该使用 java.nio.charset.CharsetDecoder。

(图片来源网络,侵删)
示例代码
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.charset.CharacterCodingException;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
import java.nio.charset.CodingErrorAction;
public class Utf8DecoderExample {
public static void main(String[] args) {
byte[] utf8Bytes = "你好,世界!😊".getBytes(StandardCharsets.UTF_8);
// 1. 获取 UTF-8 的 Charset 对象
Charset charset = StandardCharsets.UTF_8;
// 2. 创建一个 CharsetDecoder
CharsetDecoder decoder = charset.newDecoder();
// 3. (可选) 设置错误处理策略
// CodingErrorAction.REPORT: 遇到非法序列时抛异常
// CodingErrorAction.IGNORE: 忽略非法序列
// CodingErrorAction.REPLACE: 用替换字符(�)替换非法序列
decoder.onMalformedInput(CodingErrorAction.REPORT);
decoder.onUnmappableCharacter(CodingErrorAction.REPORT);
// 4. 将字节数组包装到 ByteBuffer 中
ByteBuffer byteBuffer = ByteBuffer.wrap(utf8Bytes);
try {
// 5. 解码,得到 CharBuffer
CharBuffer charBuffer = decoder.decode(byteBuffer);
// 6. 从 CharBuffer 中获取 String
String decodedString = charBuffer.toString();
System.out.println("使用 Decoder 解码后的 String: " + decodedString);
// 输出: 使用 Decoder 解码后的 String: 你好,世界!😊
} catch (CharacterCodingException e) {
System.err.println("解码失败: " + e.getMessage());
e.printStackTrace();
}
}
}
何时使用 CharsetDecoder?
- 当你需要处理非常大的数据流时,可以分块解码,避免一次性加载所有数据到内存。
- 当你需要自定义错误处理策略时。
- 当你需要将结果直接存入
CharBuffer或Writer,而不是String时。
手动解析(不推荐,仅用于理解原理)
警告: 在实际生产代码中,强烈不建议手动解析 UTF-8,这不仅容易出错,而且性能不佳,下面的代码仅用于帮助你理解 UTF-8 的编码规则。
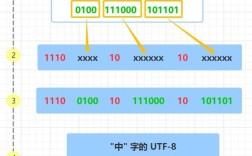
UTF-8 的编码规则如下:
- 1字节:
0xxxxxxx - 2字节:
110xxxxx 10xxxxxx - 3字节:
1110xxxx 10xxxxxx 10xxxxxx - 4字节:
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
示例代码
import java.util.ArrayList;
import java.util.List;
public class ManualUtf8Parser {
public static void main(String[] args) {
byte[] utf8Bytes = "你好".getBytes(StandardCharsets.UTF
(图片来源网络,侵删)