Selenium Python 完整教程:从零到自动化测试大师
目录
-
第一部分:初识 Selenium
 (图片来源网络,侵删)
(图片来源网络,侵删)- 1 什么是 Selenium?
- 2 为什么选择 Selenium + Python?
- 3 Selenium 的四大组件
-
第二部分:环境搭建
- 1 安装 Python
- 2 安装 Selenium 库
- 3 安装浏览器驱动
- 手动下载与配置 (推荐新手理解)
- 使用
webdriver-manager自动管理 (强烈推荐)
-
第三部分:Selenium 核心 API 详解
- 1 第一个自动化脚本:打开和关闭浏览器
- 2 定位网页元素:八大定位方式
- 3 元素交互操作
- 4 获取页面信息
- 5 等待元素加载:显式等待 vs 隐式等待
- 6 处理多窗口/多标签页
- 7 处理下拉框
- 8 处弹窗
- 9 复选框和单选框
- 10 上传文件
- 11 执行 JavaScript
-
第四部分:实战项目
- 1 项目目标:自动化登录 B 站并获取用户信息
- 2 项目代码实现与讲解
-
第五部分:高级技巧与最佳实践
 (图片来源网络,侵删)
(图片来源网络,侵删)- 1 使用无头模式
- 2 使用选项参数配置浏览器
- 3 截图功能
- 4 页面滚动
- 5 处 iframe 框架
-
第六部分:总结与进阶
第一部分:初识 Selenium
1 什么是 Selenium?
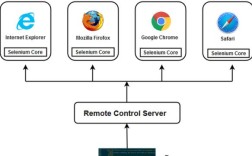
Selenium 是一个用于 Web 应用程序测试的工具,Selenium 测试直接在浏览器中运行,就像真实用户在操作一样,它支持多种浏览器(如 Chrome, Firefox, Edge)和多种操作系统(如 Windows, macOS, Linux)。
你可以用 Selenium 编写脚本,让程序代替你自动打开浏览器、访问网站、点击按钮、输入文字、获取数据等。
2 为什么选择 Selenium + Python?
- Python 语法简洁易学:Python 的代码可读性高,学习曲线平缓,让你能更专注于自动化逻辑本身,而不是复杂的语法。
- 强大的社区支持:Python 拥有全球最大的开发者社区之一,遇到任何问题,你几乎都能在 Stack Overflow、GitHub 或各种论坛上找到答案。
- 丰富的第三方库:除了 Selenium,Python 还有
pytest,unittest(测试框架),BeautifulSoup,lxml(数据解析),pandas(数据处理) 等库,可以与 Selenium 无缝集成,构建强大的自动化解决方案。 - 跨平台性:Python 脚本可以在任何安装了 Python 解释器的操作系统上运行。
3 Selenium 的四大组件
- Selenium IDE:一个浏览器插件,用于录制和回放脚本,适合快速创建测试用例原型,但灵活性较差。
- Selenium WebDriver:核心组件,它是一个 API,可以与浏览器进行“直接”通信,通过代码驱动浏览器执行操作,我们本教程将主要学习 WebDriver。
- Selenium Grid:用于分布式测试,可以让你在不同的机器和浏览器上并行运行测试用例,大大提高测试效率。
- Selenium RC (Remote Control):已废弃,是 Selenium WebDriver 的前身。
第二部分:环境搭建
1 安装 Python
如果你还没有安装 Python,请访问 Python 官网 下载并安装,安装时,请务必勾选 "Add Python to PATH" 选项。

安装完成后,打开终端或命令提示符,输入 python --version 检查是否安装成功。
2 安装 Selenium 库
打开终端或命令提示符,使用 pip (Python 的包管理器) 来安装 Selenium:
pip install selenium
3 安装浏览器驱动
WebDriver 是一个独立的程序,负责与特定的浏览器进行通信,你需要为你的浏览器下载对应的驱动。
- Chrome 浏览器驱动:ChromeDriver 下载页面
- Firefox 浏览器驱动:geckodriver 下载页面
手动下载与配置 (推荐新手理解)
- 确定你的 Chrome 浏览器版本,在 Chrome 地址栏输入
chrome://version/查看。 - 下载对应版本的 ChromeDriver,在 ChromeDriver 下载页面,找到与你浏览器版本最匹配的版本下载,通常选择
win32版本即可,因为它在 64 位系统上也能运行。 - 配置环境变量,将下载好的
chromedriver.exe文件放到一个固定的路径(C:\WebDriver),然后将这个路径添加到系统的PATH环境变量中,这样 Python 才能找到它。
缺点:每次更新浏览器后,都需要重新下载和配置驱动,非常麻烦。
使用 webdriver-manager 自动管理 (强烈推荐)
这个库可以自动检测你浏览器的版本,并自动下载和配置对应的驱动,无需手动操作。
-
安装
webdriver-manager:pip install webdriver-manager
-
在代码中使用:你只需要在脚本中导入它,它会自动处理一切。
from selenium import webdriver from selenium.webdriver.chrome.service import Service as ChromeService from webdriver_manager.chrome import ChromeDriverManager # 自动下载并设置驱动路径 driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install())) # ... 你的自动化代码 ... driver.quit()
优点:一劳永逸,无需关心驱动版本问题,是现代 Selenium 开发的最佳实践。
第三部分:Selenium 核心 API 详解
1 第一个自动化脚本
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from time import sleep # 导入 time 模块用于演示
# 1. 初始化 WebDriver
# 使用 webdriver-manager 自动管理驱动
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# 2. 打开一个网页
driver.get("https://www.baidu.com")
# 3. 打印页面标题
print("页面标题是:", driver.title)
# 4. 让脚本暂停 5 秒,方便观察 (实际项目中应避免使用 sleep)
sleep(5)
# 5. 关闭浏览器
driver.quit()
2 定位网页元素:八大定位方式
自动化脚本的核心就是操作页面上的元素(如按钮、输入框、链接等),首先需要找到这些元素,Selenium 提供了 8 种定位方式:
| 定位方式 | Python 代码示例 | 描述 |
|---|---|---|
| ID | driver.find_element(By.ID, "kw") |
通过元素的 id 属性定位,最常用且最稳定。 |
| NAME | driver.find_element(By.NAME, "wd") |
通过元素的 name 属性定位。 |
| CLASS_NAME | driver.find_element(By.CLASS_NAME, "s_ipt") |
通过元素的 class 属性定位。 |
| TAG_NAME | driver.find_element(By.TAG_NAME, "input") |
通过元素的标签名定位(如 div, a)。 |
| LINK_TEXT | driver.find_element(By.LINK_TEXT, "新闻") |
通过完整的链接文本定位超链接。 |
| PARTIAL_LINK_TEXT | driver.find_element(By.PARTIAL_LINK_TEXT, "闻") |
通过部分链接文本定位超链接。 |
| CSS_SELECTOR | driver.find_element(By.CSS_SELECTOR, "#kw") |
功能强大,推荐,通过 CSS 选择器定位。 |
| XPATH | driver.find_element(By.XPATH, '//*[@id="kw"]') |
功能最强大,推荐,通过 XPath 路径定位。 |
使用方法:
首先需要导入 By 模块:
from selenium.webdriver.common.by import By
示例:定位百度搜索框
# ... (driver 初始化代码) ...
driver.get("https://www.baidu.com")
# 方法1: 通过ID定位
search_box_by_id = driver.find_element(By.ID, "kw")
# 方法2: 通过NAME定位
search_box_by_name = driver.find_element(By.NAME, "wd")
# 方法3: 通过CSS_SELECTOR定位 (推荐)
search_box_by_css = driver.find_element(By.CSS_SELECTOR, "#kw") # #代表ID
search_box_by_css2 = driver.find_element(By.CSS_SELECTOR, "input.s_ipt") # 标签名+class
# 方法4: 通过XPATH定位 (推荐)
search_box_by_xpath = driver.find_element(By.XPATH, '//*[@id="kw"]') // 代表任意标签
3 元素交互操作
找到元素后,就可以对其进行操作。
.send_keys():在输入框中输入文字。.click():点击元素(按钮、链接等)。.clear():清空输入框的内容。
示例:在百度搜索框输入“Selenium”并点击搜索
# ... (driver 初始化和打开百度) ...
search_box = driver.find_element(By.ID, "kw")
search_button = driver.find_element(By.ID, "su")
search_box.send_keys("Selenium")
search_button.click()
4 获取页面信息
.text:获取元素的可见文本。.get_attribute("属性名"):获取元素的属性值,如id,name,href,src等。.title:获取页面标题。.current_url:获取当前页面的 URL。
示例:
# ... (搜索之后) ...
# 获取搜索结果的第一个结果的标题
first_result = driver.find_element(By.CSS_SELECTOR, "div.content_left > div.result.c-container h3")
print("第一个搜索结果的标题是:", first_result.text)
# 获取百度 logo 的链接
logo = driver.find_element(By.CSS_SELECTOR, "img#lg")
logo_src = logo.get_attribute("src")
print("百度Logo的链接是:", logo_src)
5 等待元素加载
由于网络原因或页面渲染需要,元素不会立即出现,直接操作不存在的元素会抛出 NoSuchElementException 异常,Selenium 提供了两种等待机制:
-
隐式等待:全局等待,在查找元素时,如果元素没有立即找到,Selenium 会等待一个指定的时间,然后再尝试查找,如果在等待时间内找到,则继续执行;如果超时,则抛出异常。
driver.implicitly_wait(10) # 隐式等待10秒
缺点:它是全局的,并且是轮询机制,不够精确。
-
显式等待:强烈推荐,针对某个特定的元素进行等待,直到该元素满足某个条件(如可见、可点击)或超时。
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC # 等待最多10秒,直到ID为"myDynamicElement"的元素可见 element = WebDriverWait(driver, 10).until( EC.visibility_of_element_located((By.ID, "myDynamicElement")) )expected_conditions(EC) 提供了很多预置的条件,如:EC.visibility_of_element_located(element): 元素可见EC.element_to_be_clickable(element): 元素可点击EC.presence_of_element_located(element): 元素存在于 DOM 中
6 处理多窗口/多标签页
当点击一个链接会打开新窗口或新标签页时,你需要切换到新的窗口才能操作。
# 获取当前所有窗口的句柄
original_window = driver.current_window_handle
# 点击一个会打开新窗口的链接
driver.find_element(By.LINK_TEXT, "打开新窗口").click()
# 获取所有窗口的句柄
for window_handle in driver.window_handles:
if window_handle != original_window:
driver.switch_to.window(window_handle)
break # 切换到新窗口后退出循环
# 现在在新窗口中操作...
print("新窗口标题:", driver.title)
# 关闭当前标签页/窗口
driver.close()
# 切换回原始窗口
driver.switch_to.window(original_window)
7 处理下拉框
使用 Select 类来处理 <select> 标签构成的下拉框。
from selenium.webdriver.support.ui import Select
# ... 定位到 select 元素 ...
select_element = driver.find_element(By.ID, "select_id")
# 创建 Select 对象
select = Select(select_element)
# 方法1: 通过索引选择 (从0开始)
select.select_by_index(1)
# 方法2: 通过 value 值选择
select.select_by_value("value_2")
# 方法3: 通过可见文本选择
select.select_by_visible_text("Option 2")
8 处理弹窗
弹窗分为两种:Alert (浏览器自带的简单弹窗) 和 Modal Dialog (自定义的、基于 HTML 的弹窗)。
处理 Alert:
# 触发一个 alert driver.find_element(By.ID, "alert_button").click() # 切换到 alert alert = driver.switch_to.alert # 获取 alert 文本 print(alert.text) # 接受 alert (点击"确定") alert.accept() # 或者取消 alert (点击"取消") # alert.dismiss()
9 复选框和单选框
处理方式与普通按钮 .click() 相同。
# 定位并勾选复选框
checkbox = driver.find_element(By.ID, "checkbox_id")
if not checkbox.is_selected(): # 检查是否已被选中
checkbox.click()
# 定位并选择单选框
radio_button = driver.find_element(By.ID, "radio_button_id")
radio_button.click()
10 上传文件
<input> 标签的 type 属性是 file,可以直接使用 .send_keys() 方法,将文件的路径作为参数传入。
# 定位到文件上传输入框
file_input = driver.find_element(By.ID, "file_upload_input")
# 发送文件路径
# 使用 os.path.join 可以更好地处理不同操作系统的路径分隔符
import os
file_path = os.path.abspath("test_data/sample.txt") # 确保文件存在
file_input.send_keys(file_path)
11 执行 JavaScript
一些复杂的操作或者页面上的元素很难通过 Selenium 的 API 来定位和操作,这时可以直接在浏览器中执行 JavaScript 代码。
# 执行简单的 JS 脚本
driver.execute_script("alert('Hello from Selenium!');")
# 滚动到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 滚动到指定元素
element = driver.find_element(By.ID, "some_element")
driver.execute_script("arguments[0].scrollIntoView();", element) # arguments[0] 代表传入的参数
# 获取 JS 执行后的返回值
result = driver.execute_script("return 1 + 2;")
print(result) # 输出 3
第四部分:实战项目
1 项目目标
自动化登录 B 站 (https://www.bilibili.com/),并成功获取到登录后用户的昵称。
难点:
- B 站有登录弹窗,需要先处理弹窗。
- 登录方式可能比较复杂(需要扫码或密码),这里我们模拟一个已经登录的状态,或者直接跳过登录,目标是获取登录后的元素。
- 页面元素加载需要等待。
2 项目代码实现与讲解
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
# 1. 初始化 WebDriver
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
driver.maximize_window() # 最大化窗口
# 2. 打开 B 站首页
driver.get("https://www.bilibili.com")
try:
# 3. 处理登录弹窗
# 显式等待,最多等待10秒,直到登录按钮出现
# 这里我们假设登录弹窗上有一个 "关闭" 按钮
# 注意:B站登录弹窗是动态的,这里仅作演示
# 更可靠的方法是等待用户信息区域出现
print("尝试处理登录弹窗...")
# 等待 "关闭" 按钮出现并点击
close_login_popup_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, ".close-icon"))
)
close_login_popup_button.click()
print("登录弹窗已关闭。")
# 4. 模拟登录 (这里我们跳过真实登录,直接去寻找已登录的元素)
# 在实际项目中,你需要使用扫码或密码登录。
# 为了演示,我们假设你已经登录,页面会显示你的用户信息。
# 我们直接去定位用户名元素。
# 5. 显式等待用户昵称元素出现
# 用户昵称的 class 可能会变,这里以一个常见的为例
print("等待用户信息加载...")
username_element = WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, ".nav-user-info .name"))
)
# 6. 获取并打印用户昵称
username = username_element.text
print(f"登录成功!当前用户昵称是: {username}")
except Exception as e:
print(f"发生错误: {e}")
print("可能原因:1. 未登录;2. 页面结构已变更。")
# 7. 暂停5秒以便观察
sleep(5)
# 8. 关闭浏览器
driver.quit()
第五部分:高级技巧与最佳实践
1 使用无头模式
无头模式是指在不打开图形界面的情况下运行浏览器,非常适合在服务器上执行自动化任务。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") # 启用无头模式
chrome_options.add_argument("--window-size=1920,1080") # 设置窗口大小,避免一些元素因窗口太小而无法定位
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://www.google.com")
print(driver.title)
driver.quit()
2 使用选项参数配置浏览器
Options 类允许你配置浏览器的各种行为,如设置代理、禁用图片、指定下载路径等。
chrome_options = Options()
# 禁用图片加载,可以加快页面加载速度
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 设置用户代理
chrome_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36")
driver = webdriver.Chrome(options=chrome_options)
3 截图功能
在自动化测试中,截图是记录错误状态的重要手段。
driver.get("https://www.example.com")
driver.save_screenshot("screenshot.png") # 保存截图到当前目录
4 页面滚动
除了执行 JavaScript,还可以使用 ActionChains。
from selenium.webdriver.common.action_chains import ActionChains
# 滚动到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 滚动到页面顶部
driver.execute_script("window.scrollTo(0, 0);")
# 使用 ActionChains 模拟拖拽滚动 (适用于特定场景)
# (需要有一个可以拖拽的元素)
# element = driver.find_element(By.ID, "draggable")
# actions = ActionChains(driver)
# actions.drag_and_by(element, 0, 300).perform()
5 处 iframe 框架
如果你要操作的元素在一个 <iframe> 或 <frame> 内部,你必须先切换到这个 frame 中,否则无法定位到里面的元素。
# 打开包含 iframe 的页面
driver.get("https://www.example.com/with-iframe")
# 方法1: 通过 ID 或 NAME 切换
# driver.switch_to.frame("frame_name")
# 方法2: 通过 WebElement 切换 (推荐,更稳定)
iframe_element = driver.find_element(By.CSS_SELECTOR, "iframe#my_frame")
driver.switch_to.frame(iframe_element)
# 现在可以在 iframe 中定位元素了
element_in_frame = driver.find_element(By.ID, "some_id_in_frame")
element_in_frame.click()
# 操作完成后,切回到主页面
driver.switch_to.default_content()
第六部分:总结与进阶
恭喜你,如果你已经学完了以上所有内容,你已经掌握了 Selenium 自动化测试的核心技能!
总结一下关键点:
- 环境:使用
pip install selenium和webdriver-manager来搭建环境,一劳永逸。 - 核心:
WebDriver是驱动浏览器的核心。 - 定位:熟练掌握
CSS_SELECTOR和XPATH这两种强大的定位方式。 - 等待:优先使用显式等待 (
WebDriverWait),避免使用sleep()。 - 实践:多写代码,尝试去自动化你日常访问的网站。
进阶方向:
- 测试框架:将你的脚本组织化,使用
unittest或pytest框架来管理测试用例、测试套件和断言。 - 数据驱动:使用 Excel、CSV 或 YAML 文件来存储测试数据,让你的脚本可以读取不同数据并执行,提高灵活性。
- 持续集成:将你的自动化测试脚本集成到 Jenkins, GitLab CI/CD 等工具中,实现代码提交后自动运行测试。
- Page Object Model (POM):一种设计模式,将页面元素和操作封装到独立的类中,使代码更易于维护和扩展。
- Selenium Grid:学习如何搭建和使用 Selenium Grid,实现分布式测试,大幅提升测试效率。
Selenium 是一个功能强大的工具,持续探索和实践是成为自动化测试专家的唯一途径,祝你学习顺利!