核心数据结构:数组 + 链表 / 红黑树
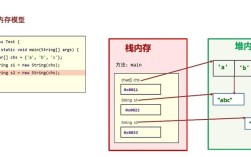
理解 HashMap 的内存,首先要理解它的核心数据结构,在 Java 8 及之后,HashMap 的底层实现是 “数组 + (链表 / 红黑树)” 的组合,也常被称为 哈希桶。

(图片来源网络,侵删)
- Node<K,V>[] table (数组): 这是
HashMap的主体,一个Node类型的数组,每个Node对象代表一个“桶”(Bucket),数组的长度(即桶的数量)是HashMap的 容量。 - Node<K,V> (链表节点):
HashMap中的每个键值对都存储在一个Node对象中,当发生哈希冲突时(即多个key计算出的哈希值指向同一个桶),这些Node对象会通过next指针连接成一个 链表。 - TreeNode<K,V> (树节点): 当链表的长度超过一个阈值(
TREEIFY_THRESHOLD,默认为 8)时,并且数组的长度也达到另一个阈值(MIN_TREEIFY_CAPACITY,默认为 64),链表会转换成更高效的 红黑树,以避免在极端情况下(所有key都冲突)查询性能退化为 O(n)。
HashMap 的内存布局
一个 HashMap 实例在内存中主要由以下几个部分组成:
-
HashMap对象本身:- 包含一些非
transient的字段,这些字段是序列化时会保留的状态。 - 主要字段包括:
Node<K,V>[] table: 指向存储键值对的数组,这是HashMap内存消耗的大头。size:HashMap中实际存储的键值对数量。loadFactor: 负载因子,用于决定何时扩容。threshold: 扩容阈值,等于capacity * loadFactor,当size超过这个值时,会触发扩容。
- 包含一些非
-
Node[]数组:- 这是
HashMap的核心存储区域,每个元素要么是null,要么是一个Node对象(或TreeNode对象)。 - 这个数组的初始容量是 16(在构造函数未指定时)。
- 这是
-
Node/TreeNode对象: (图片来源网络,侵删)
(图片来源网络,侵删)- 每个键值对都会被封装成一个
Node对象。 Node对象的结构(简化):static class Node<K,V> implements Map.Entry<K,V> { final int hash; // key的哈希值 final K key; // key的引用 V value; // value的引用 Node<K,V> next; // 指向下一个节点(链表用) // ... 构造函数、方法等 }TreeNode对象的结构更复杂,因为它需要维护红黑树的父、左、右等指针。
- 每个键值对都会被封装成一个
内存消耗的关键因素
HashMap 的内存占用主要由以下几个因素决定:
a. 容量
- 定义:
Node[] table数组的长度。 - 特点: 容量永远是 2 的幂次方(如 16, 32, 64, 128...),这是为了在计算桶索引时使用高效的位运算(
hash & (capacity - 1)),并保证哈希值分布均匀。 - 影响: 容量是
HashMap内存占用的最主要部分,一个容量为 1024 的HashMap,即使它只存 1 个键值对,也会预先分配一个能容纳 1024 个Node引用的数组。避免创建过大的HashMap至关重要。
b. 负载因子
- 定义: 一个衡量
HashMap拥挤程度的浮点数,默认值为 75。 - 作用: 决定了何时进行扩容,扩容的阈值
threshold = capacity * loadFactor。- 默认容量 16,负载因子 0.75,则阈值为
16 * 0.75 = 12,当size达到 13 时,HashMap就会进行扩容。
- 默认容量 16,负载因子 0.75,则阈值为
- 影响:
- 高负载因子 (如 0.9): 桶中元素更多,空间利用率高,但哈希冲突概率增大,链表/树变长,查询效率降低。
- 低负载因子 (如 0.5): 桶中元素稀疏,查询效率高,但空间利用率低,浪费内存。
- 默认值 0.75 是在时间和空间成本之间做出的一个很好的折中。
c. 实际存储的元素数量
- 这是最直观的内存消耗,每存一个键值对,就会创建一个
Node对象。Node对象本身有对象头、hash、key、value、next等字段,会有一定的内存开销(12-16 字节,取决于 JVM)。
d. Key 和 Value 的内存占用
HashMap存储的是key和value的 引用,而不是对象本身(除非是基本类型,其包装类也是引用)。key和value对象本身会占用堆内存。key或value是非常大的对象,HashMap的整体内存消耗也会随之增大。
扩容机制:内存增长的核心
当 HashMap 中的元素数量 size 超过 threshold 时,就会触发 扩容。
- 创建新数组: 创建一个容量是原来 两倍 的新
Node[]数组。 - 重新计算索引并迁移元素: 遍历旧数组中的每一个
Node,重新计算它在新数组中的位置,然后迁移过去。- 因为新容量是 2 的幂,所以一个元素在新数组中的位置要么是原位置,要么是
原位置 + 旧容量,这个特性使得迁移过程非常高效。
- 因为新容量是 2 的幂,所以一个元素在新数组中的位置要么是原位置,要么是
- 链表/树拆分: 在迁移过程中,原来在一个桶中的链表或红黑树可能会被拆分成两个,分别放在新数组的两个不同位置上。
扩容的代价:
- 内存: 瞬间占用双倍的内存(新旧数组同时存在)。
- CPU: 需要遍历所有元素并重新计算哈希,这是一个非常耗时的操作,时间复杂度为 O(n)。
频繁的扩容是 HashMap 性能和内存上的大忌。
内存优化策略
基于以上原理,我们可以采取以下策略来优化 HashMap 的内存使用:
a. 合理预估初始容量
这是最重要的优化手段,如果你大致知道 HashMap 会存多少个元素,可以在创建时就指定一个足够大的初始容量,以避免后续的多次扩容。
- 公式:
initialCapacity = (expectedSize / loadFactor) + 1 - 示例: 如果你预计要存放 1000 个元素,使用默认负载因子 0.75。
initialCapacity = (1000 / 0.75) + 1 ≈ 1334- 由于容量必须是 2 的幂次方,最接近且不小于 1334 的是 2048。
- 最佳实践是:
new HashMap<>(2048);
这样,HashMap 在添加 1000 个元素时,不会发生任何扩容,性能和内存都非常稳定。
b. 使用更紧凑的 Key
HashMap通过key.hashCode()来计算哈希值。key是一个复杂对象(如包含很多字段的POJO),确保其hashCode()方法实现高效且分布均匀,可以减少链表/树的长度,间接优化了查询时的内存访问效率。- 尽量使用简单的、内存占用小的对象作为
key。
c. 考虑使用 WeakHashMap
- 如果你的
key是不需要强引用的“缓存”数据,可以考虑使用WeakHashMap。 - 它的
key是 弱引用,当key没有其他强引用指向它时,垃圾回收器可以在下次回收时将其回收掉,WeakHashMap会自动移除对应的条目。 - 这非常适合实现缓存,可以防止内存溢出,但代价是
WeakHashMap的并发性能较差,且扩容时可能会因为key被回收而产生“空洞”。
d. 避免在 HashMap 中存储 null 值(过多)
- 虽然允许,但过多的
null值没有实际意义,却占用了Node对象的内存。
e. 使用 JDK 8+ 的新特性
- Java 8 引入的红黑树优化,极大地改善了在大量哈希冲突情况下的查询性能(从 O(n) 到 O(log n)),虽然对内存占用没有直接减少,但通过提升性能,可以让你在可接受的时间内处理更大的数据集,从而间接优化了内存使用的效率。
| 概念 | 定义 | 对内存的影响 |
|---|---|---|
| 数据结构 | 数组 + 链表/红黑树 | 核心内存模型,Node[] 数组是主要消耗。 |
| 容量 | Node[] 数组的长度,总是 2 的幂。 |
最主要的内存消耗,容量越大,内存占用越高。 |
| 负载因子 | 决定扩容时机的浮点数(默认 0.75)。 | 影响空间利用率,高负载因子节省内存但降低性能。 |
| 扩容 | 容量翻倍,并重新哈希所有元素。 | 瞬间消耗双倍内存,且是 CPU 密集型操作,应极力避免。 |
| Key/Value | 存储的是引用。 | 引用指向的对象本身也占用内存。 |
| 优化核心 | 合理预估初始容量,以避免扩容。 | 一次性分配足够的内存,换取后续的稳定性能和低内存开销。 |
理解 HashMap 的内存机制,关键在于抓住 “容量” 和 “扩容” 这两个核心点,通过在初始化时进行合理的容量规划,可以极大地提升应用的性能和内存效率。