SnownLP 是一个专门针对中文文本处理的 Python 库,非常流行,它集成了中文分词、词性标注、情感分析、关键词提取、文本摘要等多种功能。

(图片来源网络,侵删)
环境准备(重要)
在安装 snownlp 之前,强烈建议您使用 Python 虚拟环境,这可以避免与您系统中的其他 Python 项目产生依赖冲突。
使用 venv 创建虚拟环境:
# 1. 创建一个名为 my_nlp_project 的虚拟环境 python -m venv my_nlp_project # 2. 激活虚拟环境 # Windows 系统 my_nlp_project\Scripts\activate # macOS / Linux 系统 source my_nlp_project/bin/activate # 激活后,您的终端提示符前会出现 (my_nlp_project)
安装 SnownLP
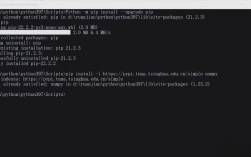
SnownLP 可以通过 Python 的包管理工具 pip 轻松安装,在您的虚拟环境中执行以下命令:
pip install snownlp
安装过程可能遇到的问题及解决方案:

(图片来源网络,侵删)
-
安装速度慢或失败: 如果您在国内,直接使用默认的 PyPI 源可能会很慢,建议使用国内镜像源,如清华大学、阿里云等。
# 使用清华镜像源安装(推荐) pip install snownlp -i https://pypi.tuna.tsinghua.edu.cn/simple # 或者使用阿里云镜像源 pip install snownlp -i https://mirrors.aliyun.com/pypi/simple/
-
依赖库问题:
snownlp依赖于numpy和jieba等库。pip通常会自动处理这些依赖,但如果遇到问题,可以尝试单独安装它们:pip install numpy jieba
验证安装
安装完成后,可以通过一个简单的 Python 脚本来验证 snownlp 是否安装成功并可以正常使用。
创建一个名为 test_snownlp.py 的文件,并粘贴以下代码:
# 导入 snownlp 库
from snownlp import SnowNLP
# 示例文本
text = "这个东西真的太棒了,我非常喜欢!"
# 创建 SnowNLP 对象
s = SnowNLP(text)
# 1. 情感分析 (返回 0 到 1 之间的浮点数,越接近 1 表示越积极)
sentiment = s.sentiments
print(f"文本: '{text}'")
print(f"情感得分: {sentiment:.2f}") # 保留两位小数
print(f"情感倾向: {'积极' if sentiment > 0.5 else '消极'}")
print("-" * 20)
# 2. 中文分词
words = s.words
print(f"分词结果: {words}")
print("-" * 20)
# 3. 关键词提取 (需要指定关键词数量)
keywords = s.keywords(3)
print(f"关键词 (Top 3): {keywords}")
print("-" * 20)
(需要指定摘要句子数量)
summary = s.summary(2)
print(f"(Top 2 句): {summary}")
然后在您的终端中运行这个脚本:
python test_snownlp.py
如果一切正常,您应该会看到类似下面的输出:
文本: '这个东西真的太棒了,我非常喜欢!'
情感得分: 0.98
情感倾向: 积极
--------------------
分词结果: ['这个', '东西', '真的', '太棒', '了', '我', '非常', '喜欢', '!']
--------------------
关键词 (Top 3): ['太棒', '喜欢', '东西']
--------------------(Top 2 句): ['这个东西真的太棒了', '我非常喜欢']常见问题与解决方案
Q1: 运行时出现 ModuleNotFoundError: No module named 'snownlp' 错误?
- 原因: Python 解释器找不到
snownlp模块,通常是因为您在一个没有安装该库的 Python 环境中运行代码。 - 解决方案:
- 确保您是在激活了虚拟环境的终端中运行
pip install。 - 确认您是在同一个虚拟环境中运行 Python 脚本,检查终端提示符。
- 如果您没有使用虚拟环境,请确保全局安装了
snownlp(pip install snownlp)。
- 确保您是在激活了虚拟环境的终端中运行
Q2: snownlp 的情感分析不准怎么办?
- 原因:
snownlp使用的是预先训练好的通用模型,它对特定领域(如金融、法律、产品评论)的文本可能表现不佳。 - 解决方案:
- 提供更多上下文: 确保分析的文本片段足够完整,不要断章取义。
- 使用更专业的库: 可以尝试
paddlepaddle的paddlenlp或THUDM的FastChat等更先进的、基于大语言模型的库,它们在情感分析等任务上通常表现更好。 - 自定义训练: 对于专业应用,可以使用自己的数据集(已标注情感)来微调
snownlp的模型,但这需要一定的机器学习知识。
Q3: snownlp 的分词效果不好?
- 原因:
snownlp内置的分词器是基于统计和规则构建的,对于新词、网络流行语或专业术语的识别能力有限。 - 解决方案:
snownlp允许用户自定义词典来添加新词或调整词频,您可以研究其lexicons目录下的文件进行修改。- 如果对分词要求很高,可以考虑使用专门的分词库,如
jieba(snownlp内部也用了它)、pkuseg或LTP等。
- 创建虚拟环境 (推荐):
python -m venv your_env_name->source/activate your_env_name。 - 安装:
pip install snownlp(可加-i https://pypi.tuna.tsinghua.edu.cn/simple加速)。 - 验证: 运行一个简单的测试脚本来确认功能正常。
- 进阶: 了解
snownlp的局限性,并根据项目需求选择更合适的工具或进行自定义优化。