使用 String 的 unescapeJava() 方法 (最简单)
这是最简单、最直接的方法,专门用于处理 Java 字符串中的转义字符,包括 Unicode 转义序列。
StringEscapeUtils 是 Apache Commons Lang 库中的一个工具类,它提供了 unescapeJava() 方法,可以轻松地将转义后的字符串转换回原始字符串。
添加依赖 (如果使用 Maven)
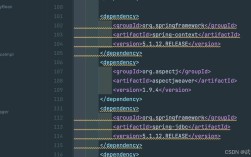
如果你的项目中没有 Apache Commons Lang 库,需要在 pom.xml 中添加依赖:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version> <!-- 使用最新的稳定版本 -->
</dependency>
代码示例
import org.apache.commons.lang3.StringEscapeUtils;
public class UnicodeConverter {
public static void main(String[] args) {
// 包含 Unicode 转义序列的字符串
String unicodeString = "\u4e2d\u56fd\u4eba\u6c11\u4e07\u5c81"; // "中国人民万岁"
// 使用 StringEscapeUtils.unescapeJava() 进行转换
String convertedString = StringEscapeUtils.unescapeJava(unicodeString);
System.out.println("原始 Unicode 字符串: " + unicodeString);
System.out.println("转换后的汉字字符串: " + convertedString);
}
}
输出:
原始 Unicode 字符串: 中国人民万岁
转换后的汉字字符串: 中国人民万岁使用 String 的 replace() 和 char 转换 (不依赖外部库)
如果你不想引入外部库,可以使用 Java 标准库来实现,原理是:
- 使用正则表达式
\\u匹配所有 Unicode 转义序列的开头。 - 对于每个匹配到的
\uXXXX,将其后的 4 个十六进制字符解析成一个char。 - 用这个
char替换掉整个\uXXXX字符串。
代码示例
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class UnicodeConverterNative {
public static void main(String[] args) {
String unicodeString = "\u4e2d\u56fd\u4eba\u6c11\u4e07\u5c81"; // "中国人民万岁"
String convertedString = convertUnicodeToChinese(unicodeString);
System.out.println("原始 Unicode 字符串: " + unicodeString);
System.out.println("转换后的汉字字符串: " + convertedString);
}
/**
* 将包含 Unicode 转义序列的字符串转换为普通字符串
* @param unicodeStr 包含 \uXXXX 格式的字符串
* @return 转换后的字符串
*/
public static String convertUnicodeToChinese(String unicodeStr) {
// 正则表达式,用于匹配 \u 开头的 Unicode 字符
Pattern pattern = Pattern.compile("\\\\u([0-9a-fA-F]{4})");
Matcher matcher = pattern.matcher(unicodeStr);
StringBuffer sb = new StringBuffer();
while (matcher.find()) {
// 将匹配到的十六进制字符串(如 "4e2d")转换为整数
int codePoint = Integer.parseInt(matcher.group(1), 16);
// 将整数转换为对应的字符
char ch = (char) codePoint;
// 用转换后的字符替换掉匹配到的整个 Unicode 序列(如 "\u4e2d")
matcher.appendReplacement(sb, String.valueOf(ch));
}
// 将剩余部分追加到结果中
matcher.appendTail(sb);
return sb.toString();
}
}
输出:
原始 Unicode 字符串: 中国人民万岁
转换后的汉字字符串: 中国人民万岁重要提醒:Java 源代码文件编码
如果你在 Java 源代码文件 (.java) 中直接写 \u4e2d\u56fd,并且你的源文件保存为 UTF-8 编码(这是现代开发的标准做法),那么你甚至不需要任何转换。
Java 编译器在读取源代码时,会自动将这些 Unicode 转义序列解释成对应的字符。
示例文件 Test.java (保存为 UTF-8 编码):
public class Test {
public static void main(String[] args) {
// 在源代码中,编译器会自动将其识别为 "中国"
String country = "\u4e2d\u56fd";
System.out.println(country); // 直接输出 "中国"
}
}
当你编译和运行这个文件时,它会直接打印出 "中国"。
什么时候才需要转换?
你通常才需要上面提到的转换方法,是在以下场景:
- 从文件或网络读取:你从一个文本文件、数据库或 API 响应中读取到了一个字符串,这个字符串的内容是
\u4e2d\u56fd的形式。 - 字符串拼接或处理:在程序运行时,你动态地构造了一个包含
\uXXXX序列的字符串,然后需要将其显示为可读的汉字。
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
StringEscapeUtils.unescapeJava() |
代码最简洁、可读性最高 | 需要引入 commons-lang3 依赖 |
推荐使用,尤其是在项目中已经使用了 Apache Commons 库时。 |
replace() + 正则表达式 |
不依赖任何外部库,纯 Java 实现 | 代码稍显复杂,需要理解正则表达式和 Matcher 的用法 |
当项目不能引入第三方库,或者希望代码完全自包含时。 |
| 直接写在源码中 | 无需任何代码,编译器自动处理 | 仅适用于源代码文件,不适用于运行时动态获取的字符串 | 在 Java 源文件中直接写 Unicode 转义序列。 |
对于大多数情况,强烈推荐使用方法一 (StringEscapeUtils.unescapeJava()),因为它最简洁、最不容易出错。