核心思想
- Python (re 模块):将正则表达式视为一个强大的工具,集成在 Python 的标准库
re模块中,它更偏向于面向过程,提供了一系列函数(re.match,re.search,re.findall等)来操作正则表达式。 - Perl (原生支持):正则表达式是 Perl 语言的核心组成部分,与语法深度集成,它拥有自己的操作符(
m//用于匹配,s///用于替换,qr//用于预编译),并且拥有大量独特的、极其强大的修饰符和语法。
详细对比
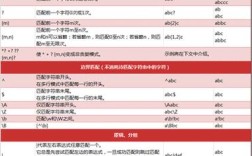
| 特性 | Python (re 模块) |
Perl | 备注 |
|---|---|---|---|
| 基本语法 | re.match(pattern, string) |
m/pattern/ 或 /pattern/ |
Python 使用函数调用,Perl 使用操作符。 |
| 分隔符 | 固定为字符串,或使用 re.compile()。 |
灵活,可以使用几乎所有非字母数字、非空格字符作为分隔符,如 m{pattern}, m#pattern#, m<pattern>。 |
Perl 的灵活性更高,便于处理包含 的路径。 |
| 修饰符 | 在函数参数中指定,如 re.IGNORECASE。 |
在分隔符后直接添加,如 /pattern/i (i 代表 ignore case)。 |
Python 的修饰符是命名常量,Perl 的是单字母缩写,更简洁。 |
| 捕获组 | (pattern) |
(pattern) |
两者语法相同,访问方式不同。 |
| 访问匹配内容 | match.group(1), match.groups() |
$1, $2, (起始位置), (结束位置) |
Python 通过 Match 对象的方法访问,Perl 通过特殊的变量(如 $1)访问。$& 表示整个匹配。 |
| 全局匹配 | re.findall() |
g 修饰符 |
Python 的 findall() 返回所有匹配的列表,Perl 中 /pattern/g 在标量上下文中返回匹配列表,在列表上下文中也返回列表。 |
| 替换 | re.sub(pattern, repl, string) |
s/pattern/repl/ |
Python 的 re.sub 功能强大,支持回调函数,Perl 的 s/// 是核心操作符,非常高效。 |
| 预编译 | re.compile() |
qr/pattern/ |
两者都提供预编译功能以提高性能,尤其是在循环中多次使用同一正则表达式时。qr// 返回一个正则对象。 |
| 特殊变量 | re.last_match (Python 3.11+) |
$_, $1, $&, , 等 |
Perl 拥有大量内置的特殊变量,使得链式操作非常方便但也可能使代码难以阅读,Python 更显式,避免副作用。 |
| 断言 | (正预查), (负预查), (?<=...) (正回顾), (?<!...) (负回顾) |
完全相同 | 两者语法和功能基本一致。 |
| 贪婪/惰性 | (贪婪), (惰性) | (贪婪), (惰性) | 两者语法相同。 |
| 命名捕获组 | (?P<name>pattern) |
(?<name>pattern) 或 ('name'pattern) |
Python 使用 P 命名语法,Perl 使用尖括号或引号,访问时,Python 用 match.group('name'),Perl 用 或 散列。 |
| 原子分组 | (?>pattern) |
(?>pattern) |
两者语法相同,用于防止回溯,提高性能。 |
| 条件表达式 | (?(condition)yes-pattern|no-pattern) |
(?(condition)yes-pattern|no-pattern) |
两者语法相同,根据条件匹配不同模式。 |
| 代码执行 | 不支持 | (?{ code }), (??{ code }) |
这是 Perl 的一个“杀手级”特性,允许在正则表达式内部执行任意 Perl 代码,实现动态生成正则等高级功能,但也带来了安全风险和性能问题,Python 完全不支持。 |
代码示例对比
基本匹配
Python

(图片来源网络,侵删)
import re
text = "Hello, World!"
pattern = r"Hello"
# re.match: 从字符串开头匹配
if re.match(pattern, text):
print("re.match: 匹配成功")
# re.search: 在字符串中任意位置匹配
if re.search(pattern, text):
print("re.search: 匹配成功")
# 使用 re.compile 预编译
regex = re.compile(pattern)
if regex.match(text):
print("预编译匹配: 成功")
Perl
use strict;
use warnings;
my $text = "Hello, World!";
my $pattern = "Hello";
# m// 操作符,默认作用于 $_
# /pattern/ 等同于 m/pattern/
if ($text =~ /Hello/) {
print "匹配成功\n";
}
# 使用 qr// 预编译
my $regex = qr/Hello/;
if ($text =~ $regex) {
print "预编译匹配: 成功\n";
}
捕获组和全局匹配
Python
import re
text = "apple, banana, cherry"
pattern = r"(\w+), (\w+), (\w+)"
match = re.search(pattern, text)
if match:
print(f"整个匹配: {match.group(0)}") # apple, banana, cherry
print(f"第一个捕获组: {match.group(1)}") # apple
print(f"所有捕获组: {match.groups()}") # ('apple', 'banana', 'cherry')
# findall 返回所有匹配的捕获组列表
all_matches = re.findall(r"(\w+)", text)
print(f"所有单词: {all_matches}") # ['apple', 'banana', 'cherry']
Perl
use strict;
use warnings;
my $text = "apple, banana, cherry";
my $pattern = "(\w+), (\w+), (\w+)";
if ($text =~ /(\w+), (\w+), (\w+)/) {
print "整个匹配: $&\n"; # apple, banana, cherry
print "第一个捕获组: $1\n"; # apple
print "所有捕获组: @+\n"; # (6 13 20) 是匹配的起始位置
print "所有捕获组: @-\n"; # (0 6 13) 是匹配的结束位置
# 获取捕获组内容
print "所有捕获组内容: $1, $2, $3\n"; # apple, banana, cherry
}
# 全局匹配
my @all_matches = $text =~ /(\w+)/g;
print "所有单词: @all_matches\n"; # apple banana cherry
替换
Python

(图片来源网络,侵删)
import re
text = "Hello, World! Hello, Universe!"
pattern = r"Hello"
# 简单替换
new_text = re.sub(pattern, "Hi", text)
print(f"简单替换: {new_text}") # Hi, World! Hi, Universe!
# 使用回调函数进行动态替换
def replace_func(match):
word = match.group(0)
return word.upper()
new_text_callback = re.sub(pattern, replace_func, text)
print(f"回调替换: {new_text_callback}") # HELLO, World! HELLO, Universe!
Perl
use strict;
use warnings;
my $text = "Hello, World! Hello, Universe!";
my $pattern = "Hello";
# 简单替换
my $new_text = $text =~ s/Hello/Hi/gr; # /r 表示返回新字符串,不修改原变量
print "简单替换: $new_text\n"; # Hi, World! Hi, Universe!
# 使用代码块进行动态替换 (e 修饰符)
$new_text = $text =~ s/Hello/sprintf("%s", uc($&))/ger;
# 解释: s///ger
# s///: 替换操作
# e: 将替换部分作为代码执行
# r: 返回结果
# uc($&) 将匹配到的整个字符串转为大写
print "代码块替换: $new_text\n"; # HELLO, World! HELLO, Universe!
命名捕获组
Python
import re
text = "John Doe, 30"
pattern = r"(?P<first>\w+) (?P<last>\w+), (?P<age>\d+)"
match = re.search(pattern, text)
if match:
print(f"First Name: {match.group('first')}")
print(f"Last Name: {match.group('last')}")
print(f"Age: {match.group('age')}")
Perl
use strict;
use warnings;
my $text = "John Doe, 30";
my $pattern = "(?<first>\w+) (?<last>\w+), (?<age>\d+)";
if ($text =~ /(?<first>\w+) (?<last>\w+), (?<age>\d+)/) {
# 使用 %+ 散列访问命名捕获组
print "First Name: $+{first}\n";
print "Last Name: $+{last}\n";
print "Age: $+{age}\n";
}
总结与选择建议
| 方面 | Python | Perl |
|---|---|---|
| 易读性 | 高,正则表达式作为字符串参数,与 Python 代码风格一致。 | 较低,大量特殊变量($1, $& 等)和操作符使得代码可能晦涩难懂。 |
| 集成度 | 中等,通过 re 模块集成,是 Python 生态系统的一部分。 |
极高,是语言的核心,语法糖和特殊变量使其与语言无缝集成。 |
| 功能 | 非常强大,覆盖了绝大多数正则表达式标准。 | 极其强大,除了标准功能,还拥有 等动态代码执行的超能力。 |
| 性能 | 良好。re.compile 可以显著提升性能。 |
极佳,作为核心功能,其引擎经过高度优化,通常比 Python 的 re 模块更快。 |
| 学习曲线 | 较平缓,对于已经懂 Python 的开发者来说很容易上手。 | 较陡峭,需要学习大量特殊变量和操作符。 |
如何选择?
-
选择 Python (
re)- 你主要在 Python 生态中工作。
- 代码可读性和可维护性是首要考虑。
- 你不需要 Perl 那种在正则内部执行代码的超高级、但通常危险的功能。
- 你的需求在正则表达式的标准规范内。
-
选择 Perl
- 你正在进行大量的文本处理、日志分析、系统管理脚本编写,这是 Perl 的传统强项。
- 你需要极致的性能和最强大的文本处理能力。
- 你需要利用 等高级特性来解决极其复杂的动态文本匹配问题。
- 你不介意学习其独特的语法和“魔法”般的特殊变量。
对于绝大多数日常应用和 Web 开发,Python 的 re 模块已经足够强大、清晰且易于使用,Perl 的正则表达式功能则更像是一个为“文本处理专家”准备的“瑞士军刀”,功能无与伦比,但也更复杂。