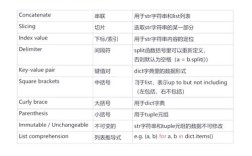
是二级Python考试的重点和难点,它考察的不仅仅是Python语言本身,更是你利用现有库解决实际问题的能力,可以理解为,这部分考试是在检验你是否“站在巨人的肩膀上”进行编程。

(图片来源网络,侵删)
什么是Python计算生态?
Python计算生态指的是由Python官方核心库、第三方库以及围绕它们形成的庞大社区、工具和资源的总和,它就像一个“应用商店”,你可以从中找到各种“工具包”(库)来完成特定的任务,而无需“重新造轮子”。
考试大纲主要考察以下几个核心领域的第三方库:
- 数据处理与分析
- 数据可视化
- 机器学习入门
- 网络爬虫
核心库详解(考试重点)
数据处理与分析库:numpy 和 pandas
这是数据处理领域的基石,也是考试的重中之重。
| 库 | 核心功能 | 常用对象/方法 | 考试重点 |
|---|---|---|---|
numpy |
高性能科学计算基础库,提供N维数组对象(ndarray)。 |
- np.array(): 创建数组- ndarray.shape: 数组形状- ndarray.dtype: 数据类型- ndarray.reshape(): 改变形状- np.mean(), np.sum(), np.max(): 统计函数 |
- 数组的创建与索引:如何从列表创建数组,如何访问数组元素(包括切片)。 - 数组的基本运算:与标量、与另一个数组的运算(注意广播机制)。 - 数组的形状操作: reshape是高频考点。 |
pandas |
数据分析核心库,基于numpy,提供了Series(一维带标签数组)和DataFrame(二维表格型数据结构)。 |
- pd.Series(): 创建Series- pd.DataFrame(): 创建DataFrame- df.head(), df.tail(): 查看前/几行- df.info(): 查看数据概况- df.describe(): 描述性统计- df['列名']: 选择列- df.loc[], df.iloc[]: 选择行/数据(核心考点)- df.dropna(): 处理缺失值- df.groupby(): 分组 |
- DataFrame的创建与基本操作:从字典、列表等创建DataFrame。- 数据选择与过滤: loc(基于标签)和 iloc(基于整数位置)是绝对的核心,必须熟练掌握。- 数据清洗:处理缺失值( dropna, fillna)。- 基本统计分析: describe, mean, sum等。- 分组聚合: groupby的使用。 |
典型考题:

(图片来源网络,侵删)
- 读取一个CSV文件(
pd.read_csv()),然后进行如下操作:- 查看数据的前5行。
- 计算某列的平均值。
- 找出“年龄”大于30的所有行。
- 将“性别”列中“男”替换为1,“女”替换为0。
- 按“城市”分组,计算每个城市的平均收入。
数据可视化库:matplotlib
matplotlib是Python最基础、最灵活的可视化库,很多其他可视化库(如seaborn)都基于它。
| 库 | 核心功能 | 常用模块/函数 | 考试重点 |
|---|---|---|---|
matplotlib |
绘制静态、动态和交互式图表的库。 | - plt.plot(): 折线图/散点图- plt.bar(): 柱状图- plt.hist(): 直方图- plt.xlabel(), plt.ylabel(): 坐标轴标签- plt.title(): 图表标题- plt.show(): 显示图表 |
- 基本图表的绘制:折线图、柱状图是必考内容。 - 图表元素的设置:如何添加标题、坐标轴标签、图例等。 - plt和Axes对象两种绘图方式的区别:考试中更常用plt的命令式风格,但了解fig, ax = plt.subplots()的方式也很重要。 |
典型考题:
- 使用
pandas读取数据后,用matplotlib绘制:- 某个数值列的折线图,展示其变化趋势。
- 不同类别的某个数值列的柱状图,并进行比较。
- 绘制一个直方图来展示数据的分布情况。
机器学习入门库:scikit-learn
scikit-learn(简称sklearn)是Python机器学习领域最经典的库,它提供了大量简单高效的工具用于数据挖掘和数据分析。
| 库 | 核心功能 | 常用模块/函数 | 考试重点 |
|---|---|---|---|
scikit-learn |
提供分类、回归、聚类、降维等机器学习算法的实现。 | - sklearn.model_selection.train_test_split(): 划分训练集和测试集- sklearn.preprocessing.StandardScaler(): 数据标准化- sklearn.linear_model.LinearRegression(): 线性回归- sklearn.neighbors.KNeighborsClassifier(): K近邻分类- model.fit(): 训练模型- model.predict(): 预测- model.score(): 评估模型准确率 |
- 机器学习基本流程:数据准备 -> 划分训练/测试集 -> 模型选择与训练 -> 模型预测与评估,这个流程必须清晰。 - fit和predict方法:这是所有模型的核心方法,必须理解其含义。- 数据预处理: train_test_split 和 StandardScaler 是高频考点。- 至少掌握一种模型:线性回归(用于预测连续值)和K近邻(用于分类)是考试中最常出现的。 |
典型考题:

(图片来源网络,侵删)
- 给定一个数据集,其中包含特征和目标(房屋特征和房价)。
- 将数据集划分为训练集和测试集。
- 使用训练集训练一个线性回归模型。
- 使用测试集进行预测,并计算模型的得分(如R²分数或准确率)。
网络爬虫库:requests 和 BeautifulSoup
这两个库是Python爬虫的“黄金搭档”。
| 库 | 核心功能 | 常用方法/属性 | 考试重点 |
|---|---|---|---|
requests |
优雅而简单的HTTP库,用于发送HTTP请求。 | - requests.get(url): 发送GET请求- response.status_code: 获取响应状态码- response.text: 获取响应文本内容- response.json(): 解析JSON响应 |
- 发送GET请求并正确处理响应(检查status_code)。- 获取网页内容( response.text)。 |
BeautifulSoup |
HTML/XML的解析库,可以从网页中提取数据。 | - BeautifulSoup(html_doc, 'html.parser'): 创建解析对象- soup.find('tag', attrs={'id': 'xxx'}): 查找单个元素- soup.find_all('tag'): 查找所有匹配元素- element.text: 获取元素的文本内容- element['attr']: 获取元素的属性 |
- 解析HTML:将requests获取的HTML内容交给BeautifulSoup解析。- 数据提取: find和find_all 是核心,需要能够根据标签名、类名、ID等定位元素并提取文本或属性。 |
典型考题:
- 编写一个爬虫程序,爬取某个简单网页(如豆瓣读书的某个图书页面)上的信息。
- 使用
requests获取目标网页的HTML。 - 使用
BeautifulSoup解析HTML。 - 找到书名、作者、评分等信息所在的HTML标签。
- 提取这些信息并打印出来。
- 使用
计算生态的拓展与使用
除了上述核心库,考试大纲还提到了:
-
jieba库:中文分词库。- 核心功能:将中文文本切分成词语。
- 常用函数:
jieba.lcut()(返回列表),jieba.lcut_for_search()(返回搜索引擎模式分词列表)。 - 考试重点:对一段中文文本进行分词,并统计词频。
-
wordcloud库:词云生成库。- 核心功能:根据文本生成词云图。
- 常用函数:
WordCloud().generate(text)生成词云,plt.imshow()显示词云。 - 考试重点:通常与
jieba库结合使用,先对中文文本分词,然后生成词云。
-
turtle库:Python标准库,用于绘图(类似LOGO语言)。- 虽然是标准库,但也属于“计算生态”的一部分。
- 考试重点:使用
turtle绘制一些基本图形,如五角星、螺旋线、分形树等,需要掌握forward,backward,left,right,penup,pendown,color,begin_fill,end_fill等命令。
备考策略与建议
- 理论与实践结合:不要只看书或看视频,一定要亲手敲代码,每个库的每个常用功能都要自己实现一遍。
- 以官方文档为准:遇到不确定的函数或参数,第一时间查阅官方文档(通常是英文,但搜索“库名+中文文档”也能找到很好的资源)。
- 掌握核心概念:对于每个库,理解其最核心的数据结构(如
ndarray,DataFrame)和最关键的函数(如loc,fit),比记住所有细节更重要。 - 多做真题和模拟题:这是最有效的备考方式,通过做题,你可以了解考试的题型、难度和侧重点,查漏补缺。
- 理解“为什么”:为什么机器学习前要划分数据集?为什么数据要标准化?理解背后的原理,能帮助你更好地记忆和使用这些库。
Python二级的“计算生态”部分,本质上是考察你作为一名“Python使用者”的综合能力,你需要知道在什么场景下使用哪个“工具库”,并且能够熟练地使用这个工具库完成任务,这部分内容庞杂,但考点相对集中,只要抓住核心库的核心功能,并进行充分的练习,就能取得好成绩,祝你考试顺利!