这是一个在 Java 编程中至关重要但又常常被误解的方法,理解它对于编写高性能、健壮的代码,尤其是在使用集合框架(如 HashMap, HashSet)时,必不可少。
方法如何正确使用?-图1")
hashCode() 是什么?
hashCode() 是 Java 中 Object 类的一个方法,这意味着每一个 Java 对象都继承了这个方法。
它的官方定义是:
返回该对象的哈希码值,这个方法是为哈希表(
HashMap提供的)提供的,以便更好地工作。通用约定:
(图片来源网络,侵删)
- 在 Java 应用程序执行期间,只要用于
equals比较的信息没有被修改,那么对同一个对象多次调用hashCode()方法,必须一致地返回同一个整数。- 如果两个对象根据
equals(Object)方法是相等的,那么调用这两个对象的hashCode()方法必须产生相同的整数结果。- 不要求:如果两个对象根据
equals(Object)方法是不相等的,那么调用这两个对象的hashCode()方法不一定需要产生不同的整数结果,程序员应该知道,为不相等的对象生成不同的哈希码值可以提高哈希表的性能。
方法如何正确使用?-图2")
hashCode() 返回一个整数值,这个值可以看作是对象的“数字指纹”或“身份证号”。
hashCode() 和 equals() 的“神圣契约”
这是理解 hashCode() 最核心、最关键的一点。hashCode() 和 equals() 之间存在着一个不可分割的约定,通常被称为 “hashCode-equals 契约” (hashCode-equals Contract)。
-
a.equals(b)为true,a.hashCode()必须等于b.hashCode()。- 解释:如果两个对象被认为是“相等”的,那么它们必须在哈希表中存储在同一个“桶”(bucket)里,为了找到同一个桶,它们的哈希码必须相同,如果违反了这一点,当你把
a放进HashMap后,再用b去查找时,会因为哈希码不同而直接去错误的桶里查找,导致get(b)返回null,即使a和b是相等的。 - 后果:严重破坏集合框架的正确性。
- 解释:如果两个对象被认为是“相等”的,那么它们必须在哈希表中存储在同一个“桶”(bucket)里,为了找到同一个桶,它们的哈希码必须相同,如果违反了这一点,当你把
-
a.hashCode()等于b.hashCode(),a.equals(b)不一定为true。方法如何正确使用?-图3") (图片来源网络,侵删)
(图片来源网络,侵删)- 解释:哈希码是一个有限的整数(32位),而对象的可能性是无限的,多个不同的对象(称为“哈希冲突”或“哈希碰撞”)可能会计算出相同的哈希码,这是完全允许的。
- 处理:当哈希表发现两个对象的哈希码相同时,它会调用
equals()方法来进一步、更精确地判断这两个对象是否真的相等。equals()返回false,说明这是一个“哈希冲突”,哈希表会通过链表或红黑树等方式将这两个对象放在同一个桶中。
-
a.equals(b)为false,a.hashCode()和b.hashCode()最好不相等。- 解释:虽然契约不强制要求,但如果两个不相等的对象有相同的哈希码,它们就会被放进同一个桶里,这会导致哈希表的性能下降,因为查找元素时需要遍历桶中的链表或红黑树,时间复杂度从接近 O(1) 退化为 O(n)。
- 目标:一个好的
hashCode()实现应该尽量为不相等的对象生成不同的哈希码,以最小化哈希冲突,从而保持哈希表的高效性。
图示说明:
+---------------------+
| HashMap |
+---------------------+
/ | \
/ | \
(bucket 1) (bucket 2) (bucket 3) ...
| | |
+----+----+ +----+----+ +----+----+
| Node A | | Node B | | Node C |
+----+----+ +----+----+ +----+----+
| | |
(hashCode=101) (hashCode=202) (hashCode=101)
查找过程:
1. 计算 key.hashCode() -> 得到 101。
2. 去哈希表中查找 hashCode=101 的桶。
3. 找到 bucket 1。
4. 遍历 bucket 1 中的节点,调用 key.equals(Node.key)。
- 如果找到相等的,则返回对应的值。
- 如果遍历完都不相等,则返回 null。为什么需要 hashCode()?—— 性能!
hashCode() 的主要目的是为了提高性能。
想象一下,如果没有 hashCode(),HashMap 是如何工作的?
它只能通过遍历所有的 key,然后对每个 key 调用 equals() 方法来查找你想要的那个,对于一个有 10,000 个元素的 HashMap,最坏情况下需要比较 10,000 次,时间复杂度是 O(n)。
有了 hashCode() 之后:
HashMap根据key的hashCode()值,可以立刻计算出这个key应该存储在哪个“桶”里。- 它不需要遍历整个
HashMap,只需要去这一个特定的桶里查找。 - 如果哈希函数设计得好,每个桶里的元素很少,那么查找就非常快,平均时间复杂度是 O(1)。
hashCode() 是哈希表能够实现快速查找的基石。
如何正确地重写 hashCode()?
当你创建一个自定义的类,并且这个类的对象需要被放入 HashSet、HashMap 或 Hashtable 中,或者你需要在 List 中查找对象时,你必须同时重写 equals() 和 hashCode() 方法。
手动重写的步骤(不推荐,易出错):
一个简单的哈希码可以这样计算:
@Override
public int hashCode() {
int result = 17; // 一个非零的初始值
result = 31 * result + (name != null ? name.hashCode() : 0);
result = 31 * result + age;
// ... 对其他字段进行同样的操作
return result;
}
- 初始值:通常选择一个非零的奇数(如 17, 31),17 是一个传统选择。
- 乘法因子:通常选择一个非零的奇数(如 31),31 是一个好选择,因为它是一个质数,
31 * i可以被优化为(i << 5) - i,这在 JVM 层面效率很高。 - 组合字段:将每个字段的哈希码组合起来,使用
31 * result + field.hashCode()的公式。 - 处理 null:如果字段可能为
null,需要处理NullPointerException。
自动生成(强烈推荐)
手动编写既繁琐又容易出错,现代的 IDE(如 IntelliJ IDEA, Eclipse)和构建工具(如 Lombok)可以一键为你生成这两个方法。
在 IntelliJ IDEA 中:
- 在类代码编辑区右键。
- 选择
Generate(或Alt + Insert)。 - 选择
equals()andhashCode()。 - IDE 会弹出一个窗口,让你选择要包含在计算中的字段,然后自动生成符合契约的代码。
使用 Lombok(更简洁):
只需在类上添加 @Data 或 @EqualsAndHashCode 注解,Lombok 会自动生成 equals(), hashCode() 和 toString() 方法。
import lombok.Data;
@Data
public class Person {
private String name;
private int age;
// ...
}
最佳实践和常见陷阱
陷阱 1:只重写 equals(),不重写 hashCode()
这是最常见的错误,如果你把这样的对象放进 HashSet 或 HashMap,会导致严重问题。
// 错误示例
public class Person {
private String name;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(name, person.name);
}
// 忘记重写 hashCode()!
}
// 后果
Set<Person> set = new HashSet<>();
Person p1 = new Person("Alice");
Person p2 = new Person("Alice");
set.add(p1);
System.out.println(set.contains(p2)); // 输出 false!
// 因为 p1.hashCode() 和 p2.hashCode() 是 Object 类的默认实现,
// 基于内存地址,所以不同,contains 方法直接根据哈希码去查找,找不到。
陷阱 2:在 hashCode() 中使用了易变对象
如果你的哈希码依赖于一个可变的字段,那么当你修改了该字段后,对象的哈希码就变了,如果这个对象已经在 HashSet 或 HashMap 的键(key)中,你将再也找不到它了。
// 危险示例
public class MutableKey {
private int value;
public MutableKey(int value) {
this.value = value;
}
@Override
public int hashCode() {
return value; // 哈希码依赖于 value
}
@Override
public boolean equals(Object o) {
// ...
}
public void setValue(int value) {
this.value = value; // value 是可变的
}
}
// 后果
Map<MutableKey, String> map = new HashMap<>();
MutableKey key = new MutableKey(100);
map.put(key, "Hello");
key.setValue(200); // 修改了 key 的状态
System.out.println(map.get(key)); // 输出 null!
// 因为现在 key 的哈希码是 200,而它在 map 中存储时用的哈希码是 100。
// map 在查找时,用新的哈希码 200 找不到旧的位置。
解决方案:永远不要将可变对象作为 HashMap 或 HashSet 的键,如果必须使用,请确保键对象是不可变的(final 字段)。
Object 类的默认 hashCode() 实现
如果你没有重写 hashCode() 方法,那么你的类将使用 Object 类提供的默认实现。
这个默认实现是根据对象的内存地址来生成一个哈希码的,这意味着,即使两个对象的内容完全相同,只要它们是两个不同的实例(内存地址不同),它们的哈希码就不同。
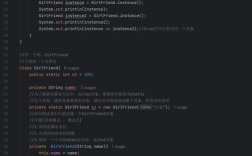
Person p1 = new Person("Alice");
Person p2 = new Person("Alice");
System.out.println(p1.hashCode()); // 输出一个基于内存地址的哈希码
System.out.println(p2.hashCode()); // 输出另一个不同的哈希码
System.out.println(p1.equals(p2)); // 取决于你是否重写了 equals,如果没重写,结果是 false
| 特性 | 描述 |
|---|---|
| 定义 | Object 类的方法,返回一个整数值,作为对象的哈希码。 |
| 核心契约 | equals() 相等的对象,hashCode() 必须相等。 |
| 主要目的 | 为哈希表(HashMap, HashSet 等)提供快速查找机制,将时间复杂度从 O(n) 优化到 O(1)。 |
| 重写时机 | 当你的类对象需要被用作 HashMap/HashSet 的键,或者需要在集合中进行精确查找时,必须同时重写 equals() 和 hashCode()。 |
| 如何重写 | 强烈推荐使用 IDE 或 Lombok 自动生成,确保正确性和效率。 |
| 常见错误 | 只重写 equals() 而忘记重写 hashCode();在 hashCode() 中使用可变字段。 |
| 默认实现 | 基于对象的内存地址,不同实例的哈希码不同。 |
掌握 hashCode() 方法是迈向 Java 高级编程的重要一步,它深刻体现了 Java 在内存管理和算法效率上的精妙设计。