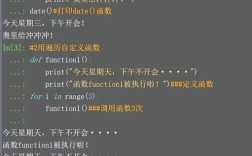
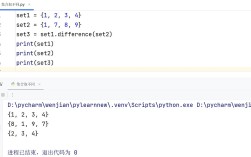
groupby 主要存在于两个地方:

(图片来源网络,侵删)
- 内置函数
itertools.groupby:主要用于对迭代器进行分组,内存效率高,但要求被分组的序列必须是已排序的。 - Pandas 库的
DataFrame.groupby():这是在数据分析中最常用的分组方法,功能强大,灵活性高,不要求原始数据排序。
下面我们分别对这两者进行详细介绍。
itertools.groupby - 迭代器分组
itertools.groupby 是 Python 标准库 itertools 中的一个函数,它返回一个迭代器,产生 (key, group_iterator) 对。
核心要点
- 输入必须是已排序的:这是
itertools.groupby最重要也最容易出错的一点,如果你对未排序的数据使用groupby,它会将相邻的相同键分到同一组,而不是将所有相同的键都归为一组。 - 惰性求值:它不会一次性将所有数据加载到内存中,而是逐个处理元素,因此非常适合处理大型数据集或流式数据。
- 返回的是迭代器:
group本身也是一个迭代器,一旦被消耗,就无法再次使用。
语法
itertools.groupby(iterable, key=None)
iterable: 一个可迭代对象。key: 一个函数,用于从每个元素中提取分组键,如果为None,则直接比较元素本身。
示例
示例 1:基本用法(已排序数据)
假设我们有一份按部门分的人员名单,并且数据已经按部门排序了。

(图片来源网络,侵删)
from itertools import groupby
# 数据已按 'department' 排序
data = [
{'name': 'Alice', 'department': 'HR'},
{'name': 'Bob', 'department': 'HR'},
{'name': 'Charlie', 'department': 'IT'},
{'name': 'David', 'department': 'IT'},
{'name': 'Eve', 'department': 'Sales'},
{'name': 'Frank', 'department': 'Sales'},
]
# 按 'department' 分组
# key=lambda x: x['department'] 表示使用字典的 'department' 值作为分组键
for key, group in groupby(data, key=lambda x: x['department']):
print(f"部门: {key}")
print(f" 成员列表: {list(group)}")
print("-" * 20)
# 输出:
# 部门: HR
# 成员列表: [{'name': 'Alice', 'department': 'HR'}, {'name': 'Bob', 'department': 'HR'}]
# --------------------
# 部门: IT
# 成员列表: [{'name': 'Charlie', 'department': 'IT'}, {'name': 'David', 'department': 'IT'}]
# --------------------
# 部门: Sales
# 成员列表: [{'name': 'Eve', 'department': 'Sales'}, {'name': 'Frank', 'department': 'Sales'}]
# --------------------
示例 2:未排序数据的错误示范
如果数据没有排序,groupby 的行为会出乎意料。
from itertools import groupby
# 数据未按 'department' 排序
unsorted_data = [
{'name': 'Alice', 'department': 'HR'},
{'name': 'Charlie', 'department': 'IT'},
{'name': 'Bob', 'department': 'HR'}, # HR 和 IT 混在一起
{'name': 'David', 'department': 'IT'},
]
print("对未排序数据使用 groupby 的错误结果:")
for key, group in groupby(unsorted_data, key=lambda x: x['department']):
print(f"键: {key}")
print(f" 组: {list(group)}")
print("-" * 20)
# 输出:
# 键: HR
# 组: [{'name': 'Alice', 'department': 'HR'}]
# --------------------
# 键: IT
# 组: [{'name': 'Charlie', 'department': 'IT'}]
# --------------------
# 键: HR <-- 错误!这里又出现了一个新的 HR 组
# 组: [{'name': 'Bob', 'department': 'HR'}]
# --------------------
# 键: IT <-- 错误!这里又出现了一个新的 IT 组
# 组: [{'name': 'David', 'department': 'IT'}]
# --------------------
正确做法:先排序,再分组
# 正确用法:先排序,再分组
sorted_data = sorted(unsorted_data, key=lambda x: x['department'])
print("\n对排序后数据使用 groupby的正确结果:")
for key, group in groupby(sorted_data, key=lambda x: x['department']):
print(f"键: {key}")
print(f" 组: {list(group)}")
print("-" * 20)
pandas.DataFrame.groupby() - 数据分析分组
在数据分析领域,pandas 的 groupby 是绝对的主力,它比 itertools.groupby 更灵活,不要求排序,并且提供了丰富的聚合、转换和过滤操作。

(图片来源网络,侵删)
核心要点
- 不要求排序:
pandas.groupby内部会处理排序逻辑,将所有相同的键分到同一组,无论它们在原始数据中的位置如何。 - 返回
DataFrameGroupBy对象:这不是一个普通的数据框,而是一个分组后的对象,它包含了分组的所有信息,你需要对其应用聚合函数(如.sum(),.mean(),.count()等)来得到最终结果。 - 功能强大:支持多种聚合操作、转换操作(如标准化)、过滤操作以及应用自定义函数。
语法
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, ...)
by: 分组的依据,可以是列名、列名列表、函数、字典等。as_index: 默认为True,表示分组键将成为结果索引,如果设为False,分组键会成为列,这在某些情况下更方便。
示例
我们使用一个经典的 DataFrame 来演示。
import pandas as pd
# 创建示例数据
data = {
'Department': ['HR', 'IT', 'HR', 'IT', 'Sales', 'Sales', 'HR'],
'Employee': ['Alice', 'Charlie', 'Bob', 'David', 'Eve', 'Frank', 'Grace'],
'Salary': [70000, 80000, 75000, 85000, 60000, 65000, 72000],
'Years': [3, 5, 2, 7, 1, 2, 4]
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)
print("\n" + "="*30 + "\n")
# 按 'Department' 分组
grouped = df.groupby('Department')
# grouped 是一个 DataFrameGroupBy 对象,不能直接打印
# print(grouped)
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x...>
# --- 常见聚合操作 ---
# 1. 计算每个部门的平均薪资
avg_salary = grouped['Salary'].mean()
print("1. 各部门平均薪资:")
print(avg_salary)
print("\n" + "="*30 + "\n")
# 2. 计算每个部门的总薪资和平均工作年限
# 一次性对多列应用不同聚合函数
# 使用 .agg() 方法
agg_results = grouped.agg(
Total_Salary=('Salary', 'sum'),
Avg_Years=('Years', 'mean')
)
print("2. 各部门薪资总和与平均工作年限:")
print(agg_results)
print("\n" + "="*30 + "\n")
# 3. 计算所有数值列的总和
# 默认对所有数值列进行聚合
sum_all = grouped.sum(numeric_only=True)
print("3. 各部门所有数值列的总和:")
print(sum_all)
print("\n" + "="*30 + "\n")
# 4. 按多个列分组
# 先按部门,再按工作年限分组
# (注意:这里数据量小,分组可能不明显)
multi_grouped = df.groupby(['Department', 'Years']).size() # .size() 计算每组大小
print("4. 按部门和年份分组后的员工数量:")
print(multi_grouped)
print("\n" + "="*30 + "\n")
# 5. 遍历分组 (类似于 itertools.groupby)
# as_index=False 让分组键成为列,方便查看
for name, group in df.groupby('Department', as_index=False):
print(f"正在处理部门: {name}")
print("该部门数据:")
print(group)
print("-" * 20)
itertools.groupby vs pandas.groupby
特性
itertools.groupbypandas.DataFrame.groupby
主要用途
对迭代器进行流式、内存高效的分组。
数据分析,对 DataFrame 进行复杂分组和聚合。
数据要求
必须已排序
无需排序,内部会处理。
输入/输出
输入任何可迭代对象,输出 (key, group_iterator) 对。
输入 DataFrame 或 Series,输出 DataFrameGroupBy 对象。
内存效率
非常高,惰性求值,适合大数据。
较低,需要将 DataFrame 加载到内存。
功能
基础的分组和迭代。
极其强大:聚合、转换、过滤、应用自定义函数等。
典型场景
日志文件逐行处理、大型文件流处理。
数据清洗、统计分析、报表生成等数据分析任务。
如何选择?
- 如果你正在处理一个巨大的、已经排好序的文件流(比如日志),并且不想把所有数据都读入内存,
itertools.groupby 是你的不二之选。
- 如果你正在进行任何形式的数据分析,数据已经在
pandas DataFrame 中,或者你需要灵活的聚合、转换功能,那么毫无疑问应该使用 pandas.groupby,在绝大多数数据分析场景下,这都是首选。
| 特性 | itertools.groupby |
pandas.DataFrame.groupby |
|---|---|---|
| 主要用途 | 对迭代器进行流式、内存高效的分组。 | 数据分析,对 DataFrame 进行复杂分组和聚合。 |
| 数据要求 | 必须已排序 | 无需排序,内部会处理。 |
| 输入/输出 | 输入任何可迭代对象,输出 (key, group_iterator) 对。 |
输入 DataFrame 或 Series,输出 DataFrameGroupBy 对象。 |
| 内存效率 | 非常高,惰性求值,适合大数据。 | 较低,需要将 DataFrame 加载到内存。 |
| 功能 | 基础的分组和迭代。 | 极其强大:聚合、转换、过滤、应用自定义函数等。 |
| 典型场景 | 日志文件逐行处理、大型文件流处理。 | 数据清洗、统计分析、报表生成等数据分析任务。 |
如何选择?
- 如果你正在处理一个巨大的、已经排好序的文件流(比如日志),并且不想把所有数据都读入内存,
itertools.groupby是你的不二之选。 - 如果你正在进行任何形式的数据分析,数据已经在
pandas DataFrame中,或者你需要灵活的聚合、转换功能,那么毫无疑问应该使用pandas.groupby,在绝大多数数据分析场景下,这都是首选。