当你在 re.split 的模式字符串中,需要匹配一个具有特殊含义的正则表达式元字符(如 ^ \ [ )时,你必须使用反斜杠 \ 对其进行转义,告诉正则表达式引擎:“请将这个字符当作普通字符来处理,而不是它的特殊含义。”

反之,如果你想在分割字符串本身中包含一个反斜杠 \,因为它是一个普通字符,你也需要对其进行转义。
下面我们分情况详细说明。
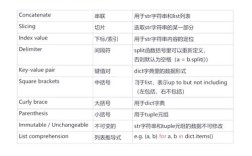
核心概念:模式字符串 vs. 分割字符串
首先要明确,转义发生在模式字符串中。
- 模式字符串:
re.split()的第一个参数,用于定义分割的规则。 - 分割字符串:
re.split()的第二个参数,即你想要实际操作的文本。
转义的目的:在模式字符串中,让元字符失去其特殊含义,使其匹配字面本身。

模式字符串中的元字符需要转义
这是最常见的情况,假设你想用句点 来分割字符串,在正则表达式中, 代表“任意单个字符”,而不是“句点”这个字面意思。
错误示例:不转义
import re
text = "apple.banana.cherry"
# 错误:. 会匹配任意字符,所以分割结果是 ['apple', 'banana', 'cherry'] 看起来好像对了,
# 但这是巧合,text 是 "appleXbananaYcherry",结果会是 ['apple', 'banana', 'cherry'],
# 这显然不是我们想要的。
# 如果字符串末尾没有字符,最后一个元素会是空字符串。
text_bad = "apple.banana."
result_bad = re.split('.', text_bad)
print(f"不转义 '.' 分割 '{text_bad}': {result_bad}")
# 输出: 不转义 '.' 分割 'apple.banana.': ['', 'a', 'n', 'a', 'n', 'a', '.']
# 解释:最后一个 '.' 匹配了它自己,后面没有字符,所以得到一个空字符串。
正确示例:转义
在 前面加上反斜杠 \,它就代表“一个字面的句点”。
import re
text = "apple.banana.cherry"
# 正确:\. 精确匹配一个句点
result_good = re.split('\.', text)
print(f"转义 '\\.' 分割 '{text}': {result_good}")
# 输出: 转义 '\.' 分割 'apple.banana.cherry': ['apple', 'banana', 'cherry']
text_with_dot_at_end = "apple.banana."
result_good_end = re.split('\.', text_with_dot_at_end)
print(f"转义 '\\.' 分割 '{text_with_dot_at_end}': {result_good_end}")
# 输出: 转义 '\.' 分割 'apple.banana.': ['apple', 'banana', '']
其他需要转义的元字符示例:
import re
text1 = "100-200-300"
# 用连字符 '-' 分割,需要转义,否则它可能表示一个范围(如 [a-z])
result1 = re.split('\-', text1)
print(f"用 '-' 分割: {result1}")
# 输出: 用 '-' 分割: ['100', '200', '300']
text2 = "apple|banana|cherry"
# 用管道符 '|' 分割,需要转义,因为它表示“或”的逻辑
result2 = re.split('\|', text2)
print(f"用 '|' 分割: {result2}")
# 输出: 用 '|' 分割: ['apple', 'banana', 'cherry']
text3 = "one(two)three"
# 用括号 '(' 或 ')' 分割,需要转义
result3 = re.split('\(', text3) # 分割开第一个 '('
print(f"用 '(' 分割: {result3}")
# 输出: 用 '(' 分割: ['one', 'two)three']
在 Python 字符串中转义反斜杠
这是一个非常重要的陷阱!在 Python 的字符串字面量中,反斜杠 \ 本身就是一个转义字符。

\n 代表换行,\t 代表制表符。
如果你想在正则表达式中匹配一个字面的反斜杠 \,你的模式字符串里需要写成 \\。
- Python 字符串层面:
\\被解释成一个单个的\。 - 正则表达式引擎层面:它接收到的是
\,然后知道要去匹配一个字面的反斜杠字符。
错误示例:不转义 Python 字符串中的反斜杠
import re
text = "C:\\Users\\Python" # 在字符串中,\\ 才代表一个 \
# 错误:模式字符串中只写了一个 \
# 这会导致 Python 语法错误或非预期的正则行为
try:
# 这会引发 SyntaxWarning,因为 \U 是一个无效的转义序列
result = re.split('\', text)
except SyntaxWarning as e:
print(f"错误: {e}")
# 更糟糕的是,如果写成这样,\ 后面跟着 ',会导致语法错误
# SyntaxError: f-string expression part cannot include a backslash
# 正确的做法是使用原始字符串(raw string)
正确示例:使用原始字符串(Raw String)
处理正则表达式时,最推荐的方法是使用原始字符串(在字符串前加 r),原始字符串会忽略所有的转义字符, \ \。
import re
text = "C:\\Users\\Python"
# 正确:使用原始字符串 r'\' 来匹配一个字面的反斜杠
# r'\' -> 正则引擎看到 '\'
result = re.split(r'\\', text)
print(f"用原始字符串 r'\\\\' 分割 '{text}': {result}")
# 输出: 用原始字符串 r'\\\\' 分割 'C:\Users\Python': ['C:', 'Users', 'Python']
分割字符串中的转义
这种情况比较简单。re.split 的第二个参数(分割字符串)是普通的文本,不需要考虑正则表达式的转义规则,你只需要确保这个字符串是按照你期望的样子传入的。
如果你有一个包含 \n 的字符串,Python 会自动将其解释为换行符。
import re
# 字符串中有一个换行符
text_with_newline = "line1\nline2\nline3"
# 用换行符 \n 分割
# 注意:模式字符串中 \n 也是换行符,不需要特殊转义(除非你想匹配字面的 'n')
result = re.split('\n', text_with_newline)
print(f"用 '\\n' 分割包含换行的字符串: {result}")
# 输出: 用 '\n' 分割包含换行的字符串: ['line1', 'line2', 'line3']
# 如果你想分割的是 "apple\nbanana" 这个包含反斜杠和n的字符串
# 你需要先构造出这个字符串
text_literal_backslash_n = "apple\\nbanana"
print(f"原始字符串内容: {text_literal_backslash_n}") # 输出: apple\nbanana
# 现在你想用 "apple\\n" 这个模式来分割
# 在模式字符串中,你需要匹配字面的 'a', 'p', 'p', 'l', 'e', '\', 'n'
# 所以模式字符串应该是 r'apple\\n'
result_literal = re.split(r'apple\\n', text_literal_backslash_n)
print(f"用字面模式 'apple\\\\n' 分割: {result_literal}")
# 输出: 用字面模式 'apple\\\\n' 分割: ['', 'banana']
总结与最佳实践
| 场景 | 目标 | Python 代码示例 | 说明 |
|---|---|---|---|
| 模式中匹配普通元字符 | 匹配 等字面字符 | re.split('\.', 'file.txt') |
在模式字符串中用 \ 转义元字符。 |
| 模式中匹配普通反斜杠 | 匹配一个字面的 \ |
re.split(r'\\', 'C:\\path') |
必须使用原始字符串 r'',写成 r'\\'。 |
| 分割字符串包含特殊字符 | 分割的文本本身有 \n 或 \t |
re.split('\n', 'line1\nline2') |
分割字符串是普通文本,无需关心转义。 |
| 复杂模式 | 同时匹配多个特殊字符 | re.split(r'[A-Z]\.', 'Version.A.1.0') |
r'' 内部 [A-Z] 是字符集,\. 是转义的句点。 |
核心要点:
-
区分模式字符串和分割字符串:转义只对模式字符串有效。
-
元字符要转义:当你在模式中想用 等字符的字面意思时,前面加
\。 -
原始字符串是你的朋友:在写正则表达式模式时,强烈推荐使用原始字符串(
r'...'),这样可以避免 Python 字符串转义和正则表达式转义之间的混淆,尤其是当需要匹配\时。 -
re.escape()函数:如果你有一个包含多种特殊字符的字符串,并且你想把它当作一个完全字面的模式来使用,可以使用re.escape()函数来自动为你转义所有元字符。import re path = "C:/Users/Python*" # 想用整个 path 字符串作为分割模式 # 手动转义很麻烦,用 re.escape() escaped_pattern = re.escape(path) # escaped_pattern 现在是 'C:\\/Users/Python\\*' text_to_split = "startC:/Users/Python*end" result = re.split(escaped_pattern, text_to_split) print(f"使用 re.escape() 分割: {result}") # 输出: 使用 re.escape() 分割: ['start', 'end']