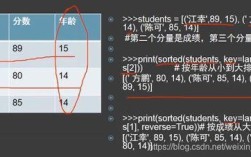
这位开发者(网名“太子龙”)以其高质量、简洁实用的 Python 工具库而闻名于国内 Python 社区,他的项目遵循 Pythonic 的设计哲学,代码风格清晰,文档完善,深受开发者喜爱。

(图片来源网络,侵删)
以下是 taizilongxu 最著名的几个 Python 项目,每一个都堪称精品:
requests-html: 强大的 HTML 解析库
这是他最广为人知的项目,是对著名库 requests 的一个功能增强版,专门用于处理网页。
-
核心功能:
- JavaScript 渲染: 可以像浏览器一样执行网页中的 JavaScript 代码,从而获取动态加载的内容,这是
requests库做不到的,通常需要借助Selenium等工具,而requests-html让这件事变得极其简单。 - CSS 选择器 和 XPath: 提供了非常方便的
find()方法,支持使用 CSS 选择器和 XPath 来定位和提取 HTML 元素,语法简洁直观。 - 便捷的 API: 提供了
get(),post()等方法发起 HTTP 请求,并可以直接在返回的Response对象上进行解析。
- JavaScript 渲染: 可以像浏览器一样执行网页中的 JavaScript 代码,从而获取动态加载的内容,这是
-
为什么好用:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 一站式解决方案: 集成了请求、JS 渲染、HTML 解析三大功能,无需组合多个库。
- 简单易学: API 设计非常符合 Python 程序员的直觉。
- 功能强大: 足以应对绝大多数的网页爬取需求。
-
简单示例:
from requests_html import HTMLSession # 创建一个会话 session = HTMLSession() # 发起 GET 请求,并执行 JS r = session.get('https://github.com/taizilongxu') # 使用 CSS 选择器找到所有仓库链接 repo_links = r.html.find('a[itemprop="name codeRepository"]') for link in repo_links: print(link.text)
fake-useragent: 生成随机 User-Agent 的库
在进行网络爬虫时,为了避免被网站封禁,经常需要随机更换 User-Agent(浏览器的身份标识)。fake-useragent 就是解决这个问题的利器。
-
核心功能:
- 海量 User-Agent 池: 内置了来自浏览器、操作系统、移动设备等的大量 User-Agent 字符串。
- 随机生成: 可以轻松地随机获取一个合法的 User-Agent。
- 自动更新: 支持从在线数据库(如
fake-useragent的 GitHub Releases)自动更新 User-Agent 列表。
-
为什么好用:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 防止反爬: 是爬虫项目中必备的工具之一。
- 使用简单: 只需一行代码就能获取一个随机 User-Agent。
- 维护及时: User-Agent 池会定期更新,能覆盖最新的浏览器版本。
-
简单示例:
from fake_useragent import UserAgent # 创建一个 UserAgent 对象 ua = UserAgent() # 随机获取一个 Chrome 浏览器的 User-Agent random_ua = ua.chrome print(random_ua) # 在 requests 中使用 import requests headers = {'User-Agent': random_ua} response = requests.get('https://www.example.com', headers=headers)
loguru: 优雅的 Python 日志库
Python 自带的 logging 模块虽然强大,但配置起来比较繁琐。loguru 提供了一个更简洁、更现代化的日志记录解决方案。
-
核心功能:
- 开箱即用: 无需复杂的配置,一行代码就能开始记录日志。
- 丰富的功能: 支持彩色输出、日志文件轮转(按大小、时间)、结构化日志、异步日志等。
- 友好的 API: 通过
add()和remove()方法灵活管理日志处理器。
-
为什么好用:
- 提升开发效率: 让日志记录变得非常轻松。
- 功能强大且专注: 专注于日志本身,提供了许多生产环境中需要的高级功能。
- 输出美观: 彩色日志能让开发者快速定位关键信息。
-
简单示例:
from loguru import logger # 直接输出到控制台,带颜色和格式 logger.debug("这是一条调试信息") logger.info("这是一条普通信息") logger.warning("这是一条警告信息") logger.error("这是一条错误信息") # 添加一个日志文件处理器,按大小轮转 logger.add("app_{time}.log", rotation="1 MB") logger.info("这条信息会同时输出到控制台和文件中。")
pypinyin: 汉字转拼音库
这是一个专门用于将汉字转换为拼音的库,功能非常全面。
-
核心功能:
- 支持多种拼音风格: 可以生成带声调的拼音(如
zhōng guó)、不带声调的拼音(如zhong guo)、首字母拼音(如zg)等。 - 多音字处理: 提供了常用多音字的词库,可以根据上下文选择正确的读音。
- 性能优秀: 转换速度快。
- 支持多种拼音风格: 可以生成带声调的拼音(如
-
为什么好用:
- 专注且专业: 专门解决汉字转拼音的问题,比通用方案更可靠。
- 配置灵活: 可以满足各种不同的拼音输出需求。
-
简单示例:
from pypinyin import pinyin, lazy_pinyin # 生成带声调的拼音列表 print(pinyin('中国人')) # [['zhōng'], ['guó'], ['rén']] # 生成不带声调的拼音列表 print(pinyin('中国人', style=pypinyin.NORMAL_STYLE)) # [['zhong'], ['guo'], ['ren']] # 生成首字母列表 print(pinyin('中国人', style=pypinyin.FIRST_LETTER)) # [['z'], ['g'], ['r']] # 懒人模式,直接拼接字符串(不带声调) print(''.join(lazy_pinyin('太子龙'))) # 'taizilong'
taizilongxu 通过这些高质量的开源项目,极大地提升了国内 Python 开发者的效率,他的作品通常具备以下特点:
- 解决实际问题: 每个项目都针对一个常见的、具体的需求。
- API 设计优秀: 遵循 Pythonic 原则,简洁、直观、易用。
- 文档完善: 提供了清晰的文档和示例,降低了学习成本。
如果你在进行 Python 开发,尤其是网络爬虫相关的工作,requests-html 和 fake-useragent 绝对是你的工具箱里必备的利器。loguru 和 pypinyin 也能在各自的领域为你提供极大的便利,强烈推荐你去他的 GitHub 主页 上看看,或许能发现更多宝藏!