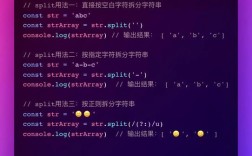
使用Java正则表达式去除HTML标签
在Java中,可以使用正则表达式来去除HTML标签,以下是几种实现方法:

(图片来源网络,侵删)
方法1:简单正则表达式
import java.util.regex.*;
public class HtmlTagRemover {
public static String removeHtmlTags(String html) {
// 正则表达式匹配HTML标签
String regex = "<[^>]+>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(html);
// 用空字符串替换所有匹配的标签
return matcher.replaceAll("");
}
public static void main(String[] args) {
String html = "<p>这是一个<b>HTML</b>示例。</p>";
String plainText = removeHtmlTags(html);
System.out.println(plainText); // 输出: 这是一个HTML示例。
}
}
方法2:更完善的正则表达式(处理自闭合标签等)
import java.util.regex.*;
public class AdvancedHtmlTagRemover {
public static String removeHtmlTags(String html) {
// 更完善的正则表达式,处理自闭合标签和注释
String regex = "<[^>]+>|<!--.*?-->";
Pattern pattern = Pattern.compile(regex, Pattern.DOTALL);
Matcher matcher = pattern.matcher(html);
return matcher.replaceAll("");
}
public static void main(String[] args) {
String html = "<div class='content'><!-- 这是一个注释 --><p>这是一个<b>HTML</b>示例。</p><br/></div>";
String plainText = removeHtmlTags(html);
System.out.println(plainText); // 输出: 这是一个HTML示例。
}
}
方法3:使用Jsoup库(推荐)
对于更复杂的HTML处理,建议使用专门的库如Jsoup,它比正则表达式更可靠:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class JsoupHtmlRemover {
public static String removeHtmlTags(String html) {
Document doc = Jsoup.parse(html);
return doc.text();
}
public static void main(String[] args) {
String html = "<div class='content'><p>这是一个<b>HTML</b>示例。</p></div>";
String plainText = removeHtmlTags(html);
System.out.println(plainText); // 输出: 这是一个HTML示例。
}
}
注意事项
- 正则表达式方法对于简单HTML有效,但对于复杂HTML(如嵌套标签、属性值中包含>等)可能不够健壮
- Jsoup方法更可靠,可以处理各种边缘情况
- 如果需要保留某些标签(如
<p>或<br>),可以修改正则表达式或使用Jsoup的白名单功能 - 对于生产环境,建议使用专门的HTML解析库而不是正则表达式
保留特定标签的示例
// 使用正则表达式保留<p>和<br>标签
public static String keepSpecificTags(String html) {
// 先移除所有标签
String noTags = html.replaceAll("<[^>]+>", "");
// 然后替换<br>为换行符
return noTags.replaceAll("<br>", "\n");
}
// 使用Jsoup保留特定标签
public static String keepSpecificTagsWithJsoup(String html) {
Document doc = Jsoup.parse(html);
doc.select("p, br").forEach(el -> {
if (el.tagName().equals("br")) {
el.after("\n");
}
});
return doc.text();
}
选择哪种方法取决于你的具体需求和HTML内容的复杂性。

(图片来源网络,侵删)