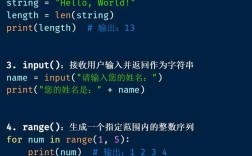
好的 使用 Python 的 requests 库下载图片

(图片来源网络,侵删)
requests 是 Python 中常用的 HTTP 库,可以方便地发送 HTTP 请求并处理响应,以下是使用 requests 下载图片的几种常见方法:
基本方法:下载并保存图片
import requests
# 图片的 URL
url = "https://example.com/image.jpg"
# 发送 GET 请求
response = requests.get(url)
# 检查请求是否成功(状态码 200)
if response.status_code == 200:
# 打开文件以二进制写入模式
with open("downloaded_image.jpg", "wb") as file:
file.write(response.content)
print("图片下载成功!")
else:
print(f"下载失败,状态码: {response.status_code}")
说明:
requests.get(url)发送 GET 请求获取图片。response.content返回图片的二进制数据。open("downloaded_image.jpg", "wb")以二进制写入模式(wb)保存文件。
添加请求头(模拟浏览器访问)
有些网站会检查请求头(如 User-Agent),如果直接请求可能会被拒绝,可以添加请求头模拟浏览器:
import requests
url = "https://example.com/image.jpg"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
with open("downloaded_image.jpg", "wb") as file:
file.write(response.content)
print("图片下载成功!")
else:
print(f"下载失败,状态码: {response.status_code}")
使用流式下载(大文件优化)
对于大图片或文件,建议使用流式下载(stream=True),避免一次性加载到内存:
import requests
url = "https://example.com/large_image.jpg"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
with requests.get(url, headers=headers, stream=True) as response:
if response.status_code == 200:
with open("large_image.jpg", "wb") as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print("大图片下载成功!")
else:
print(f"下载失败,状态码: {response.status_code}")
说明:
stream=True启用流式下载。iter_content(chunk_size=8192)分块读取数据,减少内存占用。
处理认证或需要登录的图片
如果图片需要登录或认证(如 Cookie、Bearer Token),可以在请求中添加:

(图片来源网络,侵删)
示例:使用 Cookie
import requests
url = "https://example.com/protected_image.jpg"
cookies = {"session_id": "your_session_id"}
response = requests.get(url, cookies=cookies)
if response.status_code == 200:
with open("protected_image.jpg", "wb") as file:
file.write(response.content)
print("图片下载成功!")
else:
print(f"下载失败,状态码: {response.status_code}")
示例:使用 Bearer Token
import requests
url = "https://example.com/api/image"
headers = {
"Authorization": "Bearer your_access_token",
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
with open("api_image.jpg", "wb") as file:
file.write(response.content)
print("图片下载成功!")
else:
print(f"下载失败,状态码: {response.status_code}")
异常处理
实际使用时建议添加异常处理,避免程序因网络问题或无效 URL 崩溃:
import requests
url = "https://example.com/image.jpg"
try:
response = requests.get(url, timeout=10) # 设置超时时间(秒)
response.raise_for_status() # 检查请求是否成功(非 2xx 状态码会抛出异常)
with open("downloaded_image.jpg", "wb") as file:
file.write(response.content)
print("图片下载成功!")
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
except IOError as e:
print(f"文件写入失败: {e}")
直接从 URL 显示图片(PIL)
如果需要直接处理图片(如显示或修改),可以使用 Pillow(PIL)库:
import requests
from PIL import Image
from io import BytesIO
url = "https://example.com/image.jpg"
try:
response = requests.get(url)
response.raise_for_status()
# 将二进制数据转换为图片对象
image = Image.open(BytesIO(response.content))
image.show() # 显示图片
print("图片显示成功!")
except Exception as e:
print(f"处理图片失败: {e}")
- 基本下载:
requests.get(url).content+ 二进制写入文件。 - 大文件优化:使用
stream=True+iter_content。 - 认证/登录:添加
cookies或Authorization头。 - 异常处理:捕获
requests.exceptions.RequestException和IOError。 - 直接处理:结合
Pillow和BytesIO。
根据实际需求选择合适的方法!

(图片来源网络,侵删)