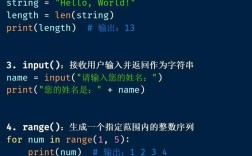
Python 生态中并没有一个官方的、统一的名为 transform 的核心库。

这个术语通常在两种不同的语境下使用:
- 作为
transformers库的简称:这是目前最常见、最强大的含义,特指由 Hugging Face 开发的、用于自然语言处理 的transformers库,它极大地推动了预训练模型(如 BERT、GPT、T5 等)的普及和使用。 - 作为一种通用的数据处理思想:在数据处理和科学计算领域,"transform" 指的是对数据进行转换、清洗、重塑的操作,这通常由
pandas、scikit-learn等库中的函数或方法来完成。
下面,我将围绕这两个方面展开详细说明。
作为 NLP 领域霸主:Hugging Face transformers 库
当人们提到 "Python transform 库" 时,99% 的情况都是指这个,它是现代 NLP 领域不可或缺的工具。
什么是 transformers 库?
transformers 是一个开源库,提供了数千个预训练的 Transformer 模型(如 BERT, RoBERTa, GPT, T5, ViT 等),以及用于微调这些模型以适应特定任务的简单易用的 API。

核心功能与优势
- 海量预训练模型:支持超过 200,000 个预训练模型,涵盖 100 多种语言。
- 简单易用的 API:提供了统一的
pipelineAPI,让非专业人士也能轻松使用强大的模型进行推理,同时也提供了底层的AutoModel和AutoTokenizer,方便进行高级定制和模型微调。 - 任务覆盖广泛:支持几乎所有主流的 NLP 任务,包括:
- 文本分类
- 命名实体识别
- 问答系统
- 文本摘要
- 机器翻译
- 文本生成
- 图像分类
- 图像分割
- 活跃的社区与生态:与
datasets、tokenizers、accelerate等库无缝集成,形成了一个完整的从数据处理、模型训练到部署的解决方案。
安装
pip install transformers
为了使用预训练模型,通常还需要安装深度学习框架作为后端,PyTorch 或 TensorFlow。
# 安装 PyTorch 后端 pip install torch # 或者安装 TensorFlow 后端 pip install tensorflow
代码示例
示例 1:使用 pipeline 进行情感分析(最简单的方式)
pipeline 是 transformers 库的“杀手级”功能,它封装了从文本分词、模型推理到结果输出的整个流程。
from transformers import pipeline
# 创建一个情感分析 pipeline
# 这会自动下载一个预训练好的模型(distilbert-base-uncased-finetuned-sst-2-english)
classifier = pipeline("sentiment-analysis")
# 对文本进行分类
result1 = classifier("I love this course! It's amazing.")
result2 = classifier("I'm not sure if I will buy this product again.")
print(result1)
# 输出: [{'label': 'POSITIVE', 'score': 0.99988...}]
print(result2)
# 输出: [{'label': 'NEGATIVE', 'score': 0.9987...}]
示例 2:加载特定模型和分词器(更灵活的方式)
如果你想使用特定的模型,可以手动加载模型和对应的分词器。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 指定模型名称
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 对文本进行分词
inputs = tokenizer("Hugging Face is making NLP accessible to everyone.", return_tensors="pt")
# 模型推理
outputs = model(**inputs)
# 获取结果 (需要处理 logits)
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
# 输出: tensor([[9.9941e-01, 5.8867e-04]], grad_fn=<SoftmaxBackward0>)
官方文档
- Hugging Face
transformers文档: https://huggingface.co/docs/transformers/index - Hugging Face 模型库: https://huggingface.co/models (在这里可以搜索和发现所有可用的模型)
作为数据处理思想:pandas 和 scikit-learn 中的 Transform
在数据科学和机器学习工作流中,"transform" 是一个核心步骤,指的是对原始数据进行转换,使其更适合建模。
pandas 中的数据转换
pandas 是 Python 数据分析的核心库,其 DataFrame 和 Series 对象提供了丰富的 .transform() 和 .apply() 方法,用于对数据进行逐行、逐列或整体的转换。
.transform() 方法:通常与一个或多个列一起使用,返回一个与原数据形状相同的 Series 或 DataFrame,常用于基于现有列创建新列。
示例:
import pandas as pd
import numpy as np
# 创建一个示例 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Score': [85, 90, 78],
'Age': [24, 27, 22]}
df = pd.DataFrame(data)
print("原始 DataFrame:")
print(df)
# 使用 transform 进行转换
# 1. 对 Score 列进行归一化 (Min-Max Scaling)
df['Score_Normalized'] = df['Score'].transform(lambda x: (x - df['Score'].min()) / (df['Score'].max() - df['Score'].min()))
# 2. 对 Age 列进行分箱
df['Age_Group'] = pd.cut(df['Age'], bins=[0, 25, 30, 100], labels=['Young', 'Adult', 'Senior'])
print("\n转换后的 DataFrame:")
print(df)
scikit-learn 中的数据转换
在机器学习中,数据转换是构建模型前至关重要的一步。scikit-learn 提供了 Transformer 类(通常继承自 BaseEstimator 和 TransformerMixin),它们是实现数据转换的标准工具。
核心概念:
fit():学习转换所需的参数(一个StandardScaler需要学习数据的均值和标准差)。transform():根据fit()学到的参数,实际应用转换。fit_transform():先fit再transform的便捷方法。
常见 Transformer 示例:
StandardScaler:将特征标准化,使其均值为 0,标准差为 1。MinMaxScaler:将特征缩放到一个指定的范围(通常是 [0, 1])。OneHotEncoder:将分类变量转换为独热编码。FunctionTransformer:允许你将任意 Python 函数包装成一个转换器。
示例:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
import pandas as pd
# 同样的数据
data = {'City': ['New York', 'London', 'Tokyo', 'New York'],
'Temperature': [15, 18, 22, 16]}
df_ml = pd.DataFrame(data)
print("原始数据:")
print(df_ml)
# 定义要对哪些列进行何种转换
# 数值特征用 StandardScaler
# 分类特征用 OneHotEncoder
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), ['Temperature']),
('cat', OneHotEncoder(), ['City'])
])
# 准备数据(scikit-learn 通常期望是 numpy 数组)
X = df_ml
# 应用转换
X_transformed = preprocessor.fit_transform(X)
print("\n转换后的数据 (numpy 数组):")
print(X_transformed)
# 输出类似于:
# [[ 0.5 1. 0. 0.]
# [-0.5 0. 1. 0.]
# [ 1.5 0. 0. 1.]
# [ 0. 1. 0. 0.]]
总结与对比
| 特性 | Hugging Face transformers |
pandas / scikit-learn 中的 Transform |
|---|---|---|
| 核心领域 | 自然语言处理 | 数据科学、机器学习 |
| 主要目的 | 使用预训练模型进行文本理解、生成等任务。 | 清洗、转换、重塑数据,使其更适合分析和建模。 |
| 操作对象 | 文本、图像等非结构化数据。 | 结构化的表格数据(DataFrame, numpy 数组)。 |
| 关键概念 | pipeline, Tokenizer, Model, pretrained, fine-tune |
fit(), transform(), fit_transform(), Scaler, Encoder |
| 典型用户 | NLP 研究员、工程师、对 AI 感兴趣的开发者。 | 数据分析师、数据科学家、机器学习工程师。 |
当你听到 "Python transform 库" 时:
- 如果你的目标是处理文本、进行机器翻译、问答或生成文本,那么你应该立即想到 Hugging Face
transformers库,它是目前该领域的绝对标准。 - 如果你的目标是清洗表格数据、进行特征工程、为机器学习模型准备数据,那么你正在谈论的是
pandas的.transform()方法 和scikit-learn的Transformer对象,它们是数据科学工作流的基础。