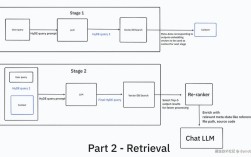
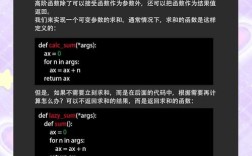
Of course! Let's break down the concept of batch size in Python, specifically in the context of machine learning and deep learning libraries like TensorFlow and PyTorch.

What is Batch Size?
In simple terms, batch size is the number of data samples processed before the model's internal parameters (weights) are updated.
Imagine you have a dataset with 1,000 images to train a model.
- Batch Size = 1: You show the model one image, calculate the error, and update the model's weights. You repeat this 1,000 times for one full pass through the data (one epoch). This is called Stochastic Gradient Descent (SGD). It's very noisy but updates the model frequently.
- Batch Size = 1,000: You show the model all 1,000 images at once, calculate the average error, and then update the model's weights once. This is called Batch Gradient Descent. It's very stable but requires a massive amount of memory and is computationally inefficient.
- Batch Size = 32 (a common choice): You show the model 32 images, calculate the average error for that small batch, and update the model's weights. You repeat this process
1000 / 32 ≈ 31times to complete one epoch. This is called Mini-Batch Gradient Descent, and it's the standard approach.
Why is Batch Size So Important?
Choosing the right batch size is a critical hyperparameter that affects several aspects of your training:
Memory (VRAM/RAM)
- Rule: Larger batch size = More memory required.
- Why: A larger batch means you are processing more data simultaneously. The model has to store the activations, gradients, and intermediate calculations for all samples in that batch in memory (usually GPU VRAM).
- Practical Impact: If your batch size is too large for your GPU, you will get a
CUDA out of memoryerror.
Computational Speed
- Rule: Larger batch size = Faster training (in terms of samples processed per second).
- Why: Modern hardware (especially GPUs) is highly optimized for parallel processing. A larger batch size allows the GPU to use its cores more efficiently, leading to better throughput. The total time for one epoch might be shorter with a larger batch size.
- Caveat: While you process samples faster, you update the model less frequently.
Model Convergence and Generalization
This is the most nuanced and important effect.

-
Noise and Generalization:
- Small Batch Size: Provides a "noisy" or "stochastic" estimate of the true gradient. This noise can be beneficial! It acts as a regularizer, helping the model escape sharp, narrow minima in the loss landscape and find flatter, more generalizable minima. This often leads to better final performance.
- Large Batch Size: Provides a very accurate, "clean" estimate of the true gradient. This leads to a more direct path to the minimum but can sometimes result in the model getting stuck in a sharp minimum that doesn't generalize as well to new, unseen data.
-
Stability and Convergence Speed:
- Small Batch Size: The frequent updates can be unstable, causing the loss to fluctuate a lot. The learning process might be slower to converge in terms of the number of epochs.
- Large Batch Size: The updates are very stable, and the loss decreases smoothly. The model often converges in fewer epochs.
How to Set Batch Size: Practical Guidelines
There is no single "best" batch size, but here are some common strategies and starting points:
Start with a Common Power of 2
Powers of 2 (e.g., 16, 32, 64, 128, 256) are popular because they align well with the memory architecture of GPUs, leading to slightly more efficient computation.

Good starting points:
- 32: A very safe and common default for many image and text classification tasks.
- 64, 128: Common for larger datasets or models where you have more VRAM.
Find the Maximum Possible Batch Size
This is a great first step. Start with a large batch size (e.g., 256 or 512) and gradually decrease it until your model trains without a CUDA out of memory error. This gives you an upper bound.
Use a Learning Rate Schedule
When you change the batch size, you should often adjust the learning rate.
- Rule of Thumb: If you multiply the batch size by
k, you should also multiply the learning rate byk. This is because the gradient is an average overkmore samples, so its magnitude is larger. - Advanced Technique: Use a learning rate warmup. With large batches, you start with a very small learning rate and gradually increase it to the target value over the first few thousand steps. This helps stabilize the initial training phase.
Experiment and Tune
The best way to find the optimal batch size is to experiment.
- Try a few values: For example, if 32 works, try 16, 64, and 128.
- Evaluate: For each batch size, train your model and evaluate its performance on a validation set. Don't just look at the training loss; look at the validation accuracy/loss to see how well the model generalizes.
Code Examples
Here’s how you specify the batch size in the most popular Python ML libraries.
TensorFlow / Keras
In Keras, you set the batch_size directly in the .fit() method.
import tensorflow as tf
from tensorflow import keras
# 1. Create a simple model
model = keras.Sequential([
keras.layers.Dense(10, activation='relu', input_shape=(784,)),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 2. Load a sample dataset (MNIST)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, 784).astype('float32') / 255.0
x_test = x_test.reshape(-1, 784).astype('float32') / 255.0
# 3. Train the model with a batch size of 64
# The data will be divided into batches of 64 samples.
print("Training with batch_size=64...")
history_64 = model.fit(
x_train,
y_train,
batch_size=64, # <--- BATCH SIZE IS SET HERE
epochs=5,
validation_split=0.2
)
# 4. Train the same model with a batch size of 32 for comparison
print("\nTraining with batch_size=32...")
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # Re-compile to reset state
history_32 = model.fit(
x_train,
y_train,
batch_size=32, # <--- BATCH SIZE IS SET HERE
epochs=5,
validation_split=0.2
)
PyTorch
In PyTorch, you typically use a DataLoader object, which handles batching, shuffling, and data loading for you.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 1. Create a simple model
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(784, 10)
self.fc2 = nn.Linear(10, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
model = SimpleModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 2. Load and prepare data (using the same MNIST data)
(x_train, y_train), (x_test, y_test) = torch.load('mnist.pt') # Or use torchvision
x_train, y_train = x_train.float() / 255.0, y_train.long()
# 3. Create a TensorDataset and a DataLoader
# The DataLoader is the key component for batching.
train_dataset = TensorDataset(x_train, y_train)
# Train with batch_size=64
print("Training with batch_size=64...")
train_loader_64 = DataLoader(
dataset=train_dataset,
batch_size=64, # <--- BATCH SIZE IS SET HERE
shuffle=True
)
for epoch in range(5):
for inputs, labels in train_loader_64:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Train with batch_size=32 for comparison
print("\nTraining with batch_size=32...")
train_loader_32 = DataLoader(
dataset=train_dataset,
batch_size=32, # <--- BATCH SIZE IS SET HERE
shuffle=True
)
for epoch in range(5):
for inputs, labels in train_loader_32:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
Summary
| Aspect | Small Batch Size | Large Batch Size |
|---|---|---|
| Memory Usage | Low | High |
| Speed (samples/sec) | Slower | Faster |
| Gradient Noise | High (acts as a regularizer) | Low (stable updates) |
| Generalization | Often better | Can be worse |
| Convergence (Epochs) | May take more epochs | Fewer epochs |
| Best For | Limited VRAM, when better generalization is needed | Large VRAM, when stable, fast training is the priority |
Final advice: Start with a batch size of 32 or 64. If you run into memory issues, decrease it. If you have a powerful GPU and want to speed things up, try increasing it, but be sure to monitor your validation performance to ensure it's not hurting your model's ability to generalize.