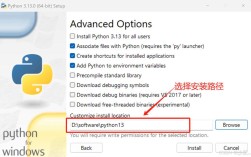
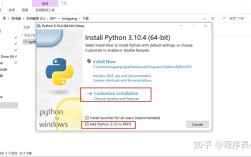
“1002”在这里可以有多种理解:

(图片来源网络,侵删)
- 一个比喻:代表从入门到精通的进阶之路,比“1001”更深入。
- 一个项目编号:可能指代一个具体的、稍复杂的爬虫项目。
- 一个挑战:暗示爬取数据时会遇到的“坑”(比如反爬机制)。
我将按照一个从基础到实战,再到高级技巧和避坑指南的完整路径来为你解读“Python爬虫1002”,这会是一份非常详尽的指南。
第一部分:Python爬虫核心基础 (入门必备)
在开始“1002”的挑战之前,确保你已经掌握了“1001”的基础知识。
核心三剑客
Requests:发送HTTP请求,获取网页的HTML内容。- 安装:
pip install requests - 核心功能:
requests.get(url),requests.post(url, data),response.text,response.status_code
- 安装:
Beautiful Soup:解析HTML/XML文档,从中提取你需要的数据。- 安装:
pip install beautifulsoup4 - 核心功能:
BeautifulSoup(html_content, 'html.parser'),soup.find(),soup.find_all(),soup.select()
- 安装:
re(正则表达式):处理字符串的利器,用于从文本中匹配复杂模式。- Python内置库,无需安装。
- 核心功能:
re.findall(pattern, string),re.search()
爬虫基本流程
一个简单的爬虫通常遵循以下步骤:
- 确定目标:明确要爬取哪个网站,以及网站上的哪些信息。
- 分析网页:使用浏览器开发者工具(F12)查看目标数据的HTML结构。
- 发送请求:使用
Requests库向目标URL发送请求,获取网页源码。 - :使用
Beautiful Soup或re解析源码,定位并提取数据。 - 保存数据:将提取的数据保存到文件(如CSV、TXT)或数据库中。
一个简单的“1001”示例:爬取豆瓣Top250电影信息
import requests
from bs4 import BeautifulSoup
import csv
# 1. 发送请求
url = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 确保编码正确
# 2. 解析内容
soup = BeautifulSoup(response.text, 'html.parser')
movie_list = soup.find_all('div', class_='item')
# 3. 提取并保存数据
with open('douban_top250.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['排名', '电影名', '评分', '评价人数']) # 写入表头
for movie in movie_list:
rank = movie.find('em').text
title = movie.find('span', class_='title').text
rating = movie.find('span', class_='rating_num').text
votes = movie.find('div', class_='star').find_all('span')[-1].text[:-3] # 去掉“人评价”三个字
writer.writerow([rank, title, rating, votes])
print("爬取完成!")
第二部分:Python爬虫1002进阶实战 (直面挑战)
我们进入“1002”阶段,这个阶段的核心是处理更复杂的网站、应对反爬策略,并构建更健壮的爬虫。

(图片来源网络,侵删)
应对反爬机制
简单的爬虫很容易被网站识别并封禁IP,现代网站有强大的反爬系统。
设置请求头
User-Agent:模拟不同浏览器访问。Referer:模拟从哪个页面跳转过来的,防止盗链。Cookie:模拟登录状态,访问需要登录的页面。
IP代理
- 当你频繁请求时,IP会被临时封禁,使用代理IP池可以更换IP,继续工作。
- 获取代理IP的网站有很多(免费的一般不稳定,付费的更可靠)。
import requests
proxies = {
'http': 'http://127.0.0.1:8080', # 本地代理,如使用Charles等抓包工具
'https': 'http://127.0.0.1:8080',
}
# 或者使用公共代理 (注意:这些代理可能不可用,仅为示例)
# proxies = {
# 'http': 'http://123.123.123.123:8080',
# 'https': 'http://123.123.123.123:8080',
# }
try:
response = requests.get('http://httpbin.org/ip', proxies=proxies, timeout=5)
print(response.json())
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
处理验证码
- 简单图形验证码:可以使用
Tesseract(OCR库) 或在线打码平台识别,但准确率不高。 - 滑动验证码/点选验证码:这是目前的主流,最可靠的方案是使用 Selenium 或 Playwright 等自动化工具模拟人的操作来完成验证。
控制爬取速度
- 使用
time.sleep()在请求之间增加随机延迟,模仿人类行为。
import time import random # 在循环中加入 time.sleep(random.uniform(1, 3)) # 随机等待1到3秒
处理动态加载的网页
很多网站(如电商、社交媒体)的数据是通过JavaScript动态加载的,直接用requests获取的HTML里没有这些数据。
解决方案:使用Selenium或Playwright
这两个库可以驱动一个真实的浏览器(如Chrome)去访问网页,等待JS执行完毕后再获取最终的页面源码。
安装Selenium和对应浏览器驱动
- 安装库:
pip install selenium - 下载对应你Chrome版本的
chromedriver,并将其路径添加到系统环境变量,或直接在代码中指定路径。
Selenium示例:爬取淘宝搜索结果
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import time
# 1. 设置浏览器驱动
driver = webdriver.Chrome() # 确保chromedriver在PATH中,或指定路径 driver = webdriver.Chrome(executable_path='path/to/chromedriver')
# 2. 访问目标网站
driver.get("https://www.taobao.com")
search_box = driver.find_element(By.ID, 'q') # 通过ID找到搜索框
search_box.send_keys("Python爬虫书籍") # 输入搜索内容
search_box.send_keys(Keys.ENTER) # 按下回车键
# 3. 等待页面加载
time.sleep(3) # 简单等待,实际项目中应使用显式等待
# 4. 获取页面源码并解析
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div', class_='item')
for item in items:= item.find('a', class_='title').text.strip()
price = item.find('strong', class_='J_Price').text
print(f"商品: {title}, 价格: {price}")
# 5. 关闭浏览器
driver.quit()
构建一个多线程/异步爬虫
当需要爬取大量页面时,单线程爬虫效率太低,使用多线程或异步IO可以大大提高效率。
多线程 (threading + queue)
- 生产者-消费者模型:一个或多个线程(生产者)负责生成URL并放入队列;多个线程(消费者)从队列中取出URL,进行爬取。
- 优点:简单易理解,适合CPU密集型或IO密集型任务。
- 缺点:线程间切换有开销,且Python的GIL(全局解释器锁)会限制多线程在CPU密集型任务上的性能。
异步IO (asyncio + aiohttp)
- 这是目前Python高并发网络编程的“王牌”方案。
- 核心思想:当发起一个网络请求(IO操作)时,程序不会等待,而是去做其他事情,当请求完成时,再通过“回调”来处理结果。