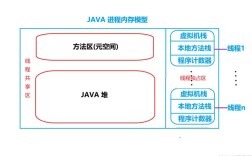
Java 内部编码与外部编码
理解这一点是解决所有编码问题的关键。

(图片来源网络,侵删)
-
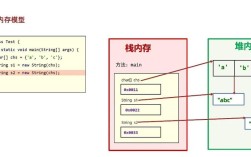
Java 内部编码 (内存中):
- Java 虚拟机(JVM)内部使用 UTF-16 编码来处理所有字符串(
String对象)。 - 当你写
String str = "你好";时,"你好" 这个字符串在内存中就是以 UTF-16 的形式存储的。 - 你通常不需要关心这个内部编码,因为 JVM 会帮你处理好,你只需要在数据进入 JVM(读入)和离开 JVM(写出)时,正确指定外部编码即可。
- Java 虚拟机(JVM)内部使用 UTF-16 编码来处理所有字符串(
-
外部编码 (文件、网络、控制台等):
- 这是指数据在文件、网络传输、数据库、控制台显示等场景下所使用的编码格式。
- UTF-8 是目前最主流的外部编码,因为它兼容 ASCII,并且对中文字符比较高效。
- 如果外部编码指定错误,就会出现乱码。
常见场景下的 UTF-8 中文处理
下面我们通过代码示例来演示在不同场景下如何正确地使用 UTF-8。
控制台输出
问题:在 Windows 的某些旧版 CMD 或 PowerShell 中直接输出中文可能会乱码。

(图片来源网络,侵删)
解决方案:确保你的控制台程序使用的编码是 UTF-8。
public class ConsoleOutput {
public static void main(String[] args) {
// 方法一:强制设置 System.out 的编码为 UTF-8(推荐)
// 这行代码应该尽可能早地执行,比如在 main 方法的开头
System.setOut(new PrintStream(System.out, true, StandardCharsets.UTF_8));
String chineseStr = "你好,世界!Hello, World!";
System.out.println(chineseStr);
// 方法二:对于 System.err (错误输出) 同理
System.setErr(new PrintStream(System.err, true, StandardCharsets.UTF_8));
System.err.println("这是一条错误信息:" + chineseStr);
}
}
注意:你的 IDE(如 IntelliJ IDEA, Eclipse)和终端(如 Windows Terminal, iTerm2)本身也需要配置为支持 UTF-8 才能正确显示。
文件读写
这是最经典的场景,使用 java.nio.file 包中的 Files 类是现代 Java 中处理文件的首选方式,因为它更简洁且不易出错。
写入文件
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.List;
public class FileWrite {
public static void main(String[] args) {
String content = "这是第一行,\n这是第二行,包含中文,This is the second line.";
Path filePath = Paths.get("output.txt");
try {
// 1. 将字符串按行分割成 List
List<String> lines = Arrays.asList(content.split("\n"));
// 2. 使用 Files.write 写入文件,并明确指定 StandardCharsets.UTF_8
// StandardCharsets.UTF_8 是一个预定义的常量,比 "UTF-8" 字符串更安全高效
Files.write(filePath, lines, StandardCharsets.UTF_8);
System.out.println("文件 'output.txt' 写入成功!");
} catch (IOException e) {
System.err.println("写入文件时出错: " + e.getMessage());
}
}
}
读取文件
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
public class FileRead {
public static void main(String[] args) {
Path filePath = Paths.get("output.txt");
try {
// 读取所有行到 List 中,并指定 UTF-8 编码
List<String> lines = Files.readAllLines(filePath, StandardCharsets.UTF_8);
// 打印读取的内容
System.out.println("文件内容:");
for (String line : lines) {
System.out.println(line);
}
} catch (IOException e) {
System.err.println("读取文件时出错: " + e.getMessage());
}
}
}
网络请求 (以 HttpClient 为例)
在 Web 开发中,处理 HTTP 请求和响应的编码至关重要。
发送 POST 请求(带 JSON 中文)
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.net.http.HttpRequest.BodyPublishers;
import java.net.http.HttpResponse.BodyHandlers;
import java.nio.charset.StandardCharsets;
public class HttpClientExample {
public static void main(String[] args) {
String jsonPayload = "{\"name\": \"张三\", \"message\": \"你好,Java!\"}";
// 创建 HttpClient
HttpClient client = HttpClient.newHttpClient();
// 创建 HttpRequest,并设置 BodyPublisher
// 注意:这里我们直接传入字符串,HttpClient 会帮我们处理编码
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://example.com/api"))
.header("Content-Type", "application/json; charset=UTF-8") // 明确告诉服务器我发的是 UTF-8
.POST(BodyPublishers.ofString(jsonPayload))
.build();
try {
// 发送请求并获取响应
HttpResponse<String> response = client.send(request, BodyHandlers.ofString());
// 检查响应状态码
if (response.statusCode() == 200) {
// 假设服务器返回的也是 UTF-8 编码的 JSON
String responseBody = response.body();
System.out.println("服务器响应: " + responseBody);
} else {
System.err.println("请求失败,状态码: " + response.statusCode());
}
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
关键点:
Content-Type头部加上; charset=UTF-8是一个好习惯,可以明确告知服务器请求体的编码。HttpClient在处理String类型的请求体和响应体时,默认会使用 UTF-8 编码,但显式声明总是更安全的。
数据库连接 (JDBC)
乱码问题经常出现在 JDBC 的 URL 连接字符串中。
错误示例(可能导致乱码):
jdbc:mysql://localhost:3306/mydb?user=root&password=123456
正确示例(明确指定字符集):
jdbc:mysql://localhost:3306/mydb?user=root&password=123456&useUnicode=true&characterEncoding=UTF-8
useUnicode=true: 启用 Unicode 字符集。characterEncoding=UTF-8: 指定连接使用的字符集为 UTF-8,这确保了从 Java 应用程序发送到 SQL 语句的字符串,以及从数据库读取到 Java 应用程序的字符串,都经过了正确的编码转换。
代码示例:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class JdbcExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=UTF-8";
String user = "root";
String password = "your_password";
try (Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT name, message FROM test_table")) {
while (rs.next()) {
// 从数据库读取数据,JDBC 会自动将 UTF-8 转换为 Java 内部的 UTF-16
String name = rs.getString("name");
String message = rs.getString("message");
System.out.println("Name: " + name + ", Message: " + message);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
总结与最佳实践
- 明确内外之分:JVM 内部是 UTF-16,所有与外部世界的交互(文件、网络、数据库)都要显式指定编码为 UTF-8。
- 优先使用
java.nio.file:进行文件 I/O 时,Files.readAllLines()和Files.write()配合StandardCharsets.UTF_8是最简单、最不容易出错的方式。 - 不要用
byte[]手动转换:除非有特殊需求,否则不要自己用String.getBytes("ISO-8859-1")这种方式去转换,让 Java 库(如HttpClient,JDBC,Files)为你处理。 - 在关键地方声明编码:
- 文件读写时指定
StandardCharsets.UTF_8。 - HTTP 请求/响应时,在
Content-Type头部加上; charset=UTF-8。 - JDBC 连接 URL 中加上
useUnicode=true&characterEncoding=UTF-8。
- 文件读写时指定
- IDE 和环境的配置:确保你的开发环境(IDE、终端、操作系统)也配置为使用 UTF-8,否则你看到的可能就是乱码,但这不是 Java 代码的问题。
遵循以上原则,你就能在 99% 的情况下避免中文乱码问题。