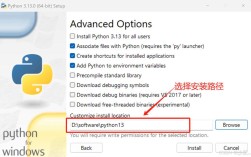
这个描述通常指的是在一个函数的调用过程中,又嵌套调用了其他函数,最终目的是为了输出(打印)某些信息,我们来通过几个经典的例子来理解。

(图片来源网络,侵删)
最简单的嵌套调用
这是最直接的理解:一个函数调用另一个函数,而那个被调用的函数负责输出。
# 函数B:负责实际打印
def say_hello():
"""这是一个简单的函数,用于打印'Hello, World!'"""
print("Hello, World!")
# 函数A:调用函数B
def greet_someone():
"""这个函数会调用另一个函数来完成打印任务"""
print("准备打招呼...")
say_hello() # 函数A调用了函数B
print("打招呼结束。")
# 现在我们调用最外层的函数A
greet_someone()
执行流程分析:
- Python解释器从上到下执行代码,遇到
greet_someone()的调用。 - 开始执行
greet_someone()函数体内的代码。 - 首先执行
print("准备打招呼..."),控制台输出:准备打招呼... - 接下来执行
say_hello(),程序的控制权暂时转移到say_hello()函数。 - 执行
say_hello()函数体内的代码print("Hello, World!"),控制台输出:Hello, World! say_hello()函数执行完毕,返回控制权给greet_someone()函数中say_hello()的下一行。- 执行
print("打招呼结束。"),控制台输出:打招呼结束。 greet_someone()函数执行完毕。
最终输出:
准备打招呼...
Hello, World!
打招呼结束。函数调用函数,并传递参数(更常见的情况)
在实际编程中,函数之间通常需要传递数据,让我们看一个更实用的例子。

(图片来源网络,侵删)
# 函数B:接收一个名字作为参数,并打印问候语
def greet_person(name):
"""根据传入的名字打印问候语"""
print(f"你好, {name}! 欢迎来到Python世界。")
# 函数A:处理一些逻辑,然后调用函数B
def process_user(user_id):
"""模拟处理用户ID,并调用问候函数"""
print(f"正在处理用户ID: {user_id}...")
# 假设我们从ID中获取了用户名
username = f"用户{user_id}"
# 调用greet_person函数,并将username作为参数传递过去
greet_person(username)
print(f"用户ID {user_id} 的处理完成。")
# 调用最外层的函数
process_user(123)
执行流程分析:
- 调用
process_user(123)。 process_user开始执行,打印正在处理用户ID: 123...。- 定义
username = "用户123"。 - 调用
greet_person(username),这等同于greet_person("用户123")。 - 程序控制权转移到
greet_person函数,参数name被赋值为"用户123"。 greet_person执行print(f"你好, {name}! ..."),输出:你好, 用户123! 欢迎来到Python世界。greet_person执行完毕,控制权返回process_user。process_user继续执行,打印用户ID 123 的处理完成。。
最终输出:
正在处理用户ID: 123...
你好, 用户123! 欢迎来到Python世界。
用户ID 123 的处理完成。链式调用(一个调用链)
这个场景更符合“函数调用函数调用函数”的字面意思,形成了一条调用链。
# 函数C:最内层,执行最核心的操作并返回结果
def get_final_data():
"""模拟从数据库或API获取最终数据"""
print(" [C] 正在从数据源获取最终数据...")
return "这是最终的数据内容"
# 函数B:中间层,调用函数C,并可能对结果进行加工
def process_data():
"""调用数据获取函数,并处理返回的数据"""
print(" [B] 正在准备获取数据...")
data_from_c = get_final_data() # 调用函数C
print(f" [B] 已获取数据,正在处理...")
processed_data = f"[已处理] {data_from_c}"
return processed_data
# 函数A:最外层,调用函数B,并输出最终结果
def display_result():
"""调用数据处理函数,并展示最终结果"""
print("[A] 开始展示最终结果")
final_result = process_data() # 调用函数B
print(f"[A] 最终结果为: {final_result}")
print("[A] 展示结束")
# 启动整个调用链
display_result()
执行流程分析(注意缩进代表的层级):

(图片来源网络,侵删)
- 调用
display_result()。 [A] 开始展示最终结果被打印。display_result调用process_data()。[B] 正在准备获取数据...被打印。process_data调用get_final_data()。[C] 正在从数据源获取最终数据...被打印。get_final_data()返回字符串"这是最终的数据内容"。- 控制权回到
process_data,data_from_c被赋值为那个字符串。 [B] 已获取数据,正在处理...被打印。process_data返回加工后的字符串"[已处理] 这是最终的数据内容"。- 控制权回到
display_result,final_result被赋值为那个加工后的字符串。 [A] 最终结果为: [已处理] 这是最终的数据内容被打印。[A] 展示结束被打印。
最终输出:
[A] 开始展示最终结果
[B] 正在准备获取数据...
[C] 正在从数据源获取最终数据...
[B] 已获取数据,正在处理...
[A] 最终结果为: [已处理] 这是最终的数据内容
[A] 展示结束- 核心概念:函数调用就像一个“任务委托”,当一个函数遇到另一个函数的调用时,它会暂停自己的当前任务,将CPU的控制权交给被调用的函数,被调用的函数执行完毕后,会返回控制权,并可能带回一个返回值,然后原函数从暂停的地方继续执行。
- 为什么这么做?
- 模块化:将一个大问题分解成多个小而独立的函数,每个函数只做一件事,使代码更清晰、更易于维护。
- 可重用性:一个函数(如
say_hello)可以在程序的多个地方被调用,避免重复代码。 - 可读性:通过函数名(如
process_user,display_result)可以清晰地表达代码的意图,使逻辑更易懂。
理解了函数的嵌套调用,你就掌握了Python编程中一个非常核心和重要的概念。