- 是什么? -
HashMap的基本定义和特性。 - 如何用? -
HashMap的常用方法和基本操作。 - 核心原理 -
HashMap是如何工作的?(底层数据结构、哈希冲突、扩容机制) - 最佳实践 - 如何高效、正确地使用
HashMap。 - 与其他 Map 的比较 -
HashMapvs.Hashtablevs.ConcurrentHashMapvs.LinkedHashMap。
是什么?HashMap 的基本定义和特性
HashMap 是 Java 集合框架中 java.util.Map 接口的一个具体实现,它存储的是 键值对 的数据。

(图片来源网络,侵删)
核心特性:
- 键值对存储:每个元素包含一个
key(键)和一个value(值)。key是唯一的,value可以重复。 - 基于哈希表:它的底层实现是 数组 + 链表/红黑树 的组合,这使得它的增、删、改、查操作的平均时间复杂度接近 O(1),效率非常高。
- 非线程安全:
HashMap不是同步的,如果在多线程环境下对同一个HashMap实例进行并发修改,可能会导致数据不一致或死循环等问题,如果需要线程安全的版本,应该使用Hashtable或ConcurrentHashMap。 - 允许 null 键和 null 值:
HashMap可以存储一个null键和多个null值,这是它与Hashtable的一个重要区别。 - 不保证有序:在 Java 8 之前,
HashMap的遍历顺序是不确定的,从 Java 8 开始,虽然保留了不保证有序的官方声明,但在某些情况下(如不发生哈希冲突和扩容时),遍历顺序看起来是按照插入顺序的。但绝对不能依赖这个特性,如果需要保持插入顺序,应使用LinkedHashMap。
如何用?HashMap 的常用方法和基本操作
创建 HashMap 对象
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// 1. 创建一个空的 HashMap,key 和 value 都是 String 类型
Map<String, String> map1 = new HashMap<>();
// 2. 创建一个指定初始容量的 HashMap
// 初始容量是 16,负载因子是 0.75
Map<String, Integer> map2 = new HashMap<>(32);
// 3. 创建一个指定初始容量和负载因子的 HashMap
Map<String, Object> map3 = new HashMap<>(64, 0.5f);
}
}
常用操作
| 方法 | 描述 | 示例 |
|---|---|---|
put(K key, V value) |
添加一个键值对。key 已存在,则覆盖其 value 并返回旧的 value;否则返回 null。 |
map.put("name", "Alice"); |
get(Object key) |
根据 key 获取对应的 value。key 不存在,则返回 null。 |
String name = map.get("name"); |
remove(Object key) |
根据 key 删除对应的键值对,并返回被删除的 value。key 不存在,则返回 null。 |
map.remove("name"); |
containsKey(Object key) |
判断 HashMap 中是否包含某个 key。 |
boolean hasName = map.containsKey("name"); |
containsValue(Object value) |
判断 HashMap 中是否包含某个 value。 |
boolean hasAlice = map.containsValue("Alice"); |
size() |
返回 HashMap 中键值对的数量。 |
int count = map.size(); |
isEmpty() |
判断 HashMap 是否为空。 |
boolean empty = map.isEmpty(); |
clear() |
清空 HashMap 中的所有键值对。 |
map.clear(); |
keySet() |
返回一个包含所有 key 的 Set 集合。 |
Set<String> keys = map.keySet(); |
values() |
返回一个包含所有 value 的 Collection 集合。 |
Collection<String> values = map.values(); |
entrySet() |
返回一个包含所有 key-value 映射的 Set 集合,类型为 Set<Map.Entry<K, V>>,最常用于遍历。 |
Set<Map.Entry<String, String>> entries = map.entrySet(); |
遍历 HashMap
有三种主要的遍历方式:
Map<String, Integer> scores = new HashMap<>();
scores.put("Alice", 95);
scores.put("Bob", 88);
scores.put("Charlie", 92);
// 1. 遍历 key
System.out.println("--- 遍历 Key ---");
for (String name : scores.keySet()) {
System.out.println("Key: " + name);
}
// 2. 遍历 value
System.out.println("\n--- 遍历 Value ---");
for (Integer score : scores.values()) {
System.out.println("Value: " + score);
}
// 3. 遍历 key-value (推荐方式)
System.out.println("\n--- 遍历 Key-Value (推荐) ---");
for (Map.Entry<String, Integer> entry : scores.entrySet()) {
System.out.println("Name: " + entry.getKey() + ", Score: " + entry.getValue());
}
// 4. 使用 Java 8+ 的 forEach 和 Lambda 表达式 (更简洁)
System.out.println("\n--- 使用 Lambda 遍历 ---");
scores.forEach((name, score) -> System.out.println("Name: " + name + ", Score: " + score));
核心原理:HashMap 是如何工作的?
理解 HashMap 的内部原理是掌握它的关键。
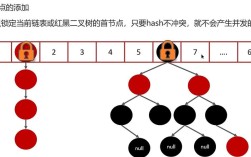
底层数据结构:数组 + (链表 / 红黑树)
HashMap 的核心是一个名为 table 的数组,数组的每个元素被称为一个 桶 或 槽。

(图片来源网络,侵删)
// 简化的内部结构示意 transient Node<K,V>[] table;
每个桶中可能存放以下三种结构之一:
Node(节点):当没有哈希冲突时,一个桶里直接存放一个Node对象。Node包含hash、key、value、next指针。TreeNode(树节点):当某个桶中的链表长度超过一个阈值(TREEIFY_THRESHOLD,默认为 8)并且数组的长度达到 64 时,链表会转换为 红黑树,以提高查询效率(从 O(n) 降到 O(log n))。null:桶为空。
工作流程:put 和 get 方法
put(K key, V value) 方法流程
-
计算
key的哈希值:- 调用
key.hashCode()方法得到原始的哈希码。 - 通过一个复杂的哈希算法(
hash()方法)对原始哈希码进行二次处理,以减少哈希冲突的概率,这个处理后的哈希值用于确定最终的位置。
- 调用
-
确定数组索引(寻址):
- 使用公式
index = (tab.length - 1) & hash来计算出key应该存放在数组的哪个索引位置(即哪个桶里)。
- 使用公式
-
处理桶中的内容:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 情况1:桶为空:直接创建一个新的
Node对象放入这个桶中。 - 情况2:桶不为空(发生哈希冲突):
- 遍历链表/红黑树:从桶中的第一个节点开始,比较
hash值和key是否相等。 - 找到相同的
key:如果找到hash和key都相等的节点,说明key已存在,则用新的value覆盖旧的value,并返回旧的value。 - 未找到相同的
key:遍历到末尾也没有找到,则在链表的末尾(或在红黑树中插入相应位置)添加一个新的Node。
- 遍历链表/红黑树:从桶中的第一个节点开始,比较
- 情况1:桶为空:直接创建一个新的
-
检查是否需要转换或扩容:
- 树化:在添加新节点后,如果桶中的元素数量(链表长度)达到 8,并且总容量
table.length大于等于 64,就会将链表转换为红黑树。 - 扩容:在添加新节点后,
HashMap中的元素数量超过了 *容量 负载因子*(默认 `16 0.75 = 12`),就会触发扩容。- 扩容操作:创建一个容量是原来两倍的新数组,然后重新计算所有
key在新数组中的位置(index),并将它们迁移到新数组中,这是一个非常消耗性能的操作。
- 扩容操作:创建一个容量是原来两倍的新数组,然后重新计算所有
- 树化:在添加新节点后,如果桶中的元素数量(链表长度)达到 8,并且总容量
get(Object key) 方法流程
- 计算
key的哈希值:与put方法一样,先计算hash值。 - 确定数组索引:使用同样的公式
index = (tab.length - 1) & hash找到对应的桶。 - 查找
value:- 如果桶是
null,直接返回null。 - 如果桶不为空,遍历该桶中的链表或红黑树。
- 在遍历过程中,比较节点的
hash和key是否与目标匹配。 - 如果找到匹配的节点,返回其
value。 - 如果遍历完都没有找到,返回
null。
- 如果桶是
最佳实践
为自定义的 key 类重写 equals() 和 hashCode()
这是使用 HashMap 最重要的一点。HashMap 依赖 hashCode() 来定位桶,依赖 equals() 来在桶内精确查找。
规则:
- 如果两个对象
a和b满足a.equals(b),那么它们必须满足a.hashCode() == b.hashCode()。 - 反之不成立。
a.hashCode() == b.hashCode(),a.equals(b)不一定为true(哈希冲突)。
示例:
class Person {
private String id;
private String name;
// 构造函数、getters...
// 必须重写 equals() 和 hashCode()
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(id, person.id); // 假设 id 是唯一标识
}
@Override
public int hashCode() {
return Objects.hash(id); // 使用唯一标识 id 来计算哈希码
}
}
// 使用
Map<Person, String> map = new HashMap<>();
Person p1 = new Person("001", "Alice");
map.put(p1, "Engineer");
// 如果不重写,下面这行代码可能会找不到值,因为默认的 hashCode() 基于内存地址
Person p2 = new Person("001", "Alice");
System.out.println(map.get(p2)); // 只有正确重写后,才会返回 "Engineer"
初始容量和负载因子的选择
-
负载因子:默认
75是一个在时间和空间成本上很好的折中,更高的值(如9)会减少空间开销但增加查找成本(哈希冲突更多),更低的值(如5)会提高查找效率但增加内存消耗。 -
初始容量:如果你能预估出大概要存储多少数据,可以设置一个合适的初始容量,以避免频繁的扩容操作。
计算公式:
初始容量 = 预期元素数量 / 负载因子// 假设要存储 1000 个元素,负载因子为 0.75 // 初始容量应至少为 1000 / 0.75 = 1333.33,向上取整为 1344 // 但容量必须是 2 的幂次方,所以选择最接近的 2 的幂次方,2048 Map<String, String> map = new HashMap<>(2048);
避免在 HashMap 中存储可变对象
作为 key 的对象应该是 不可变 的,如果在对象被放入 HashMap 后,它的 hashCode() 值发生了变化,HashMap 将无法再找到这个 key,导致数据“丢失”。
与其他 Map 的比较
| 特性 | HashMap |
Hashtable |
ConcurrentHashMap |
LinkedHashMap |
|---|---|---|---|---|
| 线程安全 | 否 | 是 (方法级同步) | 是 (分段锁/CAS) | 否 |
| 性能 | 高 | 低 (所有操作加锁) | 高 (锁粒度细) | 略低于 HashMap |
| Null 键/值 | 允许 1 个 null 键,多个 null 值 |
不允许 | 不允许 | 允许 1 个 null 键,多个 null 值 |
| 有序性 | 无序 | 无序 | 无序 | 按插入顺序 遍历有序 |
| 继承/实现 | AbstractMap |
Dictionary |
AbstractMap |
HashMap |
| 推荐场景 | 单线程环境,默认选择 | 已过时,不推荐使用 | 多线程高并发环境 | 需要按插入顺序访问键值对的场景 |
HashMap 是 Java 开发中不可或缺的工具,它的核心优势在于基于哈希表的 O(1) 平均时间复杂度的操作,理解其 数组 + 链表/红黑树 的底层数据结构、put/get 的工作流程以及哈希冲突的解决方法,对于写出高效、健壮的代码至关重要,牢记为自定义 key 重写 equals() 和 hashCode() 的最佳实践,并根据场景选择合适的 Map 实现类。