核心原理
Java 中的 String 类使用的是 UTF-16 编码,这是其内部表示,它不关心字符串最初是从哪种编码来的,转换过程总是遵循以下两步:
- 解码:将源编码(GBK)的字节流,按照 GBK 的字符集规则,转换成 Java 的
String对象。 - 编码:将
String对象,按照目标编码(UTF-8)的规则,转换成新的字节流。
将 GBK 编码的字节数组转换为 UTF-8 编码的字节数组
这是最常见的需求,例如处理从文件或网络中读取的 GBK 编码数据。
方法:使用 String 的构造函数和 String.getBytes() 方法
import java.nio.charset.StandardCharsets;
public class GbkToUtf8Bytes {
public static void main(String[] args) {
// 原始的 GBK 编码的字节数组
// "你好" 这两个汉字在 GBK 编码中占 4 个字节
// '你' -> 0xC4, 0xE3
// '好' -> 0xBA, 0xC3
byte[] gbkBytes = {(byte) 0xC4, (byte) 0xE3, (byte) 0xBA, (byte) 0xC3};
// --- 转换步骤 ---
// 1. 将 GBK 字节数组解码成 Java String
// 指定使用 GBK 字符集来解释这些字节
String gbkString = new String(gbkBytes, "GBK");
System.out.println("解码后的字符串: " + gbkString); // 输出: 你好
System.out.println("字符串的字符长度: " + gbkString.length()); // 输出: 2
// 2. 将 String 重新编码成 UTF-8 字节数组
// 指定使用 UTF-8 字符集来生成字节
byte[] utf8Bytes = gbkString.getBytes(StandardCharsets.UTF_8);
// 或者使用 "UTF-8" 字符串(不推荐,容易拼写错误)
// byte[] utf8Bytes = gbkString.getBytes("UTF-8");
System.out.println("转换后的 UTF-8 字节数组长度: " + utf8Bytes.length); // 输出: 6 (UTF-8 中,一个汉字通常占3个字节)
System.out.println("UTF-8 字节数组内容: ");
for (byte b : utf8Bytes) {
System.out.printf("%02X ", b); // 输出: E4 BD A0 E5 A5 BD
}
}
}
代码解释:
new String(gbkBytes, "GBK"):这是关键的一步,它告诉 Java,gbkBytes这个字节数组是按照 GBK 编码规则组织的,Java 会按照这个规则,将这些字节映射成对应的字符,形成一个String。gbkString.getBytes(StandardCharsets.UTF_8):这一步将String对象转换回字节流,我们指定了目标编码为UTF-8,Java 会将字符串中的每个字符按照 UTF-8 的规则转换成 1 到 4 个字节。
重要提示:从 Java 7 开始,推荐使用 java.nio.charset.StandardCharsets 类中预定义的常量(如 StandardCharsets.UTF_8, StandardCharsets.ISO_8859_1),而不是直接使用字符串(如 "UTF-8"),这样可以避免因拼写错误导致的 UnsupportedCharsetException。
将 GBK 编码的文件内容读取并另存为 UTF-8 文件
这是场景一的实际应用,我们需要处理文件 I/O。
方法:使用 InputStreamReader 和 OutputStreamWriter
这种方法更高效,因为它可以逐字符或逐行处理,而不需要一次性将整个文件读入内存。
import java.io.*;
public class GbkFileToUtf8File {
public static void convert(String sourceGbkFilePath, String targetUtf8FilePath) throws IOException {
// 1. 创建 GBK 编码的 InputStreamReader
// 它负责将 GBK 字节流解码为字符流 (Reader)
try (InputStreamReader isr = new InputStreamReader(new FileInputStream(sourceGbkFilePath), "GBK");
// 2. 创建 UTF-8 编码的 OutputStreamWriter
// 它负责将字符流 (Writer) 编码为 UTF-8 字节流
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(targetUtf8FilePath), StandardCharsets.UTF_8)) {
char[] buffer = new char[8192]; // 8KB 的缓冲区
int length;
// 3. 循环读取字符并写入
while ((length = isr.read(buffer)) != -1) {
osw.write(buffer, 0, length);
}
System.out.println("文件转换完成: " + sourceGbkFilePath + " -> " + targetUtf8FilePath);
}
}
public static void main(String[] args) {
String sourceFile = "source_gbk.txt"; // 假设这是一个 GBK 编码的文件
String targetFile = "target_utf8.txt"; // 这是将要生成的 UTF-8 文件
try {
// 为了演示,先创建一个 GBK 编码的源文件
createGbkFile(sourceFile);
// 执行转换
convert(sourceFile, targetFile);
} catch (IOException e) {
e.printStackTrace();
}
}
// 辅助方法:创建一个 GBK 编码的测试文件
private static void createGbkFile(String filename) throws IOException {
try (OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(filename), "GBK")) {
writer.write("这是 GBK 编码的文件,\n");
writer.write("Hello, GBK to UTF-8!\n");
writer.write("包含中文和英文。");
}
System.out.println("已创建 GBK 编码文件: " + filename);
}
}
代码解释:
InputStreamReader(..., "GBK"):将FileInputStream(字节流)包装起来,并指定其源编码为 GBK,这样,read()方法读取的就是字符,而不是原始字节。OutputStreamWriter(..., StandardCharsets.UTF_8):将FileOutputStream(字节流)包装起来,并指定其目标编码为 UTF-8,这样,write()方法写入的字符会被自动转换成 UTF-8 字节再写入文件。- 使用
try-with-resources语句可以自动关闭流,是 Java 7+ 的最佳实践。
解决常见的编码问题(“乱码”)
乱码通常是因为编码和解码时使用的字符集不一致导致的。
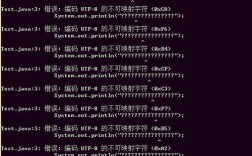
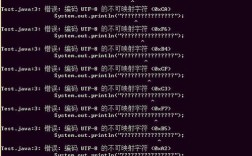
问题1:从 GBK 文件中读取,但错误地当作 UTF-8 读取
现象显示为 或一堆无意义的符号。
原因:文件本身是 GBK 编码,但代码中使用了 new String(bytes, "UTF-8") 或 new InputStreamReader(new FileInputStream(file), "UTF-8") 来读取,Java 用错误的“密码本”(UTF-8)去解读“密码”(GBK字节),自然得到错误的结果。
解决方案:确保读取时使用的字符集与文件的实际编码一致。 请参考场景二的方法。
问题2:从 UTF-8 文件中读取,但错误地当作 GBK 读取
现象:通常一个 UTF-8 字符(如汉字)被拆分成两个 GBK 字符,导致显示不完整或乱码。
原因:与上面相反,文件是 UTF-8,但代码用 GBK 的“密码本”去解读。
解决方案:确保读取时使用的字符集与文件的实际编码一致。
问题3:从数据库或网络获取的字节数据是 GBK,但直接用 new String(bytes) 转换
现象:出现乱码。
原因:当没有指定字符集时,new String(byte[]) 会使用 JVM 的默认字符集(通常是操作系统的默认编码,如 Windows 可能是 GBK,Linux/macOS 通常是 UTF-8),如果数据源是 GBK,而 JVM 默认是 UTF-8,就会乱码。
解决方案:永远不要使用无参的 new String(byte[])。 必须明确指定数据的原始编码。
// 错误的做法 (依赖于 JVM 默认编码) // String str = new byteDataFromDb; // 可能乱码 // 正确的做法 byte[] gbkDataFromDb = getFromDatabase(); // 假设这个方法返回 GBK 字节数组 String correctString = new String(gbkDataFromDb, "GBK"); // 明确指定为 GBK
| 转换需求 | 核心代码 | 关键点 |
|---|---|---|
| 字节数组互转 | new String(gbkBytes, "GBK").getBytes(StandardCharsets.UTF_8) |
指定源编码解码成 String。指定目标编码从 String 生成字节数组。 |
| 文件互转 | InputStreamReader(..., "GBK") + OutputStreamWriter(..., StandardCharsets.UTF_8) |
使用字符流包装字节流,并正确指定源和目标编码。 |
| 避免乱码 | 明确指定字符集,不要依赖 JVM 默认编码。 | 始终问自己:“这些字节的原始编码是什么?” |
记住这个核心流程:字节流 -> (解码) -> 字符串 -> (编码) -> 新字节流,并在每一步使用正确的字符集,你就能轻松处理各种编码转换问题。