- 核心思想:数组 + 链表/红黑树
- 关键概念:哈希、哈希冲突
- 核心操作:
put方法详解 - 核心操作:
get方法详解 - 扩容机制
- Java 8 的重要优化:引入红黑树
- 总结与特性
核心思想:数组 + 链表/红黑树
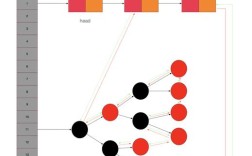
HashMap 的本质是一个 “数组的链表”(或者更准确地说是“数组的链表/红黑树”),它内部维护了一个数组,我们称之为 “桶数组” (Bucket Array)。

- 数组:提供了快速访问(通过索引)的能力,查找效率为 O(1)。
- 链表/红黑树:当多个元素的哈希值冲突时,它们会被放在同一个“桶”中,以链表或红黑树的形式组织起来。
这个结构完美地结合了数组的快速定位和链表的动态扩容特性。
简单比喻: 想象一个有 10 个格子的储物柜(数组),每个格子都有一个编号(索引)。
- 你有一个
key为 "Apple" 的物品,通过某种计算(哈希函数)得出它应该放在第 3 号格子,你直接把 "Apple" 放进去。 - 后来你又有一个
key为 "Banana" 的物品,计算后发现它也应该放在第 3 号格子,这时,你不能把 "Banana" 直接扔进去,而是把它挂在 "Apple" 后面,形成一个链表(链表)。 - 当第 3 号格子的物品越来越多时(比如超过 8 个),为了提高查找效率,这个链表就会被转换成一个更高效的 红黑树 结构。
关键概念:哈希、哈希冲突
哈希
HashMap 中的每个元素都是一个键值对,要快速找到这个元素,不能通过遍历,必须通过 key 来定位。
哈希 就是一个将任意长度的输入(key)通过一个算法(key.hashCode())转换成一个固定长度的输出(一个整数)的过程,这个整数就是 哈希码。

在 Java 中,Object 类提供了 hashCode() 方法,所有 Java 对象都继承了这个方法。
哈希冲突
理想情况下,不同的 key 应该计算出不同的哈希码,但由于哈希码的范围是固定的(32 位整数),而 key 的数量可能是无限的,不同的 key 可能计算出相同的哈希码,这种现象就是 哈希冲突。
HashMap 的核心任务就是如何优雅地处理哈希冲突。
核心操作:put 方法详解
当你调用 map.put(key, value) 时,内部发生了以下步骤:

步骤 1:计算 key 的哈希值
- 调用
key.hashCode()方法得到一个原始的哈希码。 - 对这个哈希码进行一次“扰动处理”(
hash()方法),目的是为了减少哈希冲突的概率,这个处理包括高 16 位异或低 16 位,使得哈希值分布更均匀。// 简化的扰动处理逻辑 static final int hash(Object key) { int h; // (h = key.hashCode()) ^ (h >>> 16) 就是扰动处理 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
步骤 2:计算数组索引(桶的位置)
- 使用
&运算符将上一步得到的哈希值与(数组长度 - 1)进行位运算,得到在数组中的存储位置(索引)。// index = (n - 1) & hash // n 是数组的长度
- 为什么用
&而不是 ?因为&运算符的效率远高于 取模运算。 - 为什么是
(n - 1)?因为数组的索引是从 0 开始的,n-1是最大的有效索引,这要求数组的长度n必须是 2 的幂次方,这样才能保证(n-1)的二进制形式全是1,从而保证&运算后能均匀地分布在所有索引上。
- 为什么用
步骤 3:处理桶中的元素
根据计算出的索引 i,去桶数组中查找:
-
情况 1:桶为空
table[i]是null,说明这个位置还没有元素。- 直接创建一个新的
Node对象(包含key,value,hash,next),并放入table[i]中。
-
情况 2:桶不为空(发生哈希冲突)
table[i]上已经有元素了,需要遍历这个桶里的链表或红黑树。- 遍历链表/树:
- 如果遍历过程中发现某个节点的
key和你正在插入的key“相等”(通过equals()方法比较),则说明是更新操作。- 将该节点的
value更新为新值,并返回旧值。
- 将该节点的
- 如果遍历完整个链表/树都没有找到相等的
key,说明这是一个全新的键值对。
- 如果遍历过程中发现某个节点的
- 插入新节点:
- 如果桶的结构是 链表:将新创建的
Node对象插入到链表的 末尾(Java 8 之前是头插法,之后改为尾插法,防止在扩容时链表出现环)。 - 如果桶的结构是 红黑树:调用树的插入方法,将新节点插入到树中,并进行平衡调整。
- 如果桶的结构是 链表:将新创建的
步骤 4:检查是否需要转换结构或扩容
- 在插入节点后,会检查当前桶中(链表或树)的元素数量
size。 size超过 8(TREEIFY_THRESHOLD),并且数组的长度 大于等于 64,就会将这个链表 转换成红黑树,以提高后续的查找效率。size超过 8,但数组长度 小于 64,说明数组太“挤”了,此时不会转换成树,而是先进行 扩容,让元素更分散。- 每次插入元素后,都会检查
HashMap中元素的总数量map.size()是否 超过扩容阈值(capacity * loadFactor),如果超过,则进行 整体扩容。
核心操作:get 方法详解
当你调用 map.get(key) 时,过程与 put 类似,但更简单:
步骤 1:计算 key 的哈希值
- 和
put方法一样,先对key.hashCode()进行扰动处理,得到最终的hash值。
步骤 2:计算数组索引
- 使用
(n - 1) & hash计算出在桶数组中的索引i。
步骤 3:查找元素
- 根据
i找到对应的桶table[i]。 - 如果桶为空,直接返回
null。 - 如果桶不为空:
- 如果桶是 链表:遍历链表,逐个比较节点的
key是否与传入的key相等(使用equals()),如果找到,返回对应的value;如果遍历完没找到,返回null。 - 如果桶是 红黑树:调用树的查找方法,在树中查找
key,如果找到返回对应的value,否则返回null。
- 如果桶是 链表:遍历链表,逐个比较节点的
扩容机制
当 HashMap 中的元素数量 size 超过 *容量 加载因子** 时,HashMap 就需要进行扩容。
- 容量:桶数组的长度,即
table.length,默认初始容量是16。 - 加载因子:一个
float类型的值,用于决定何时扩容,默认是75。- 默认扩容阈值:
16 * 0.75 = 12,当HashMap中存入第 13 个元素时,就会触发扩容。
- 默认扩容阈值:
扩容过程:
- 创建一个新的桶数组,新数组的容量是 旧数组的两倍。
- 遍历旧数组中的每一个元素。
- 对于每个元素(可能是一个链表或一棵红黑树),需要重新计算它们在新数组中的位置。
- 这里的一个巧妙之处是:因为新数组的长度是旧数组的两倍,
(n-1)的二进制表示只是多了一个最高位的1。 - 一个元素的
hash值在新旧数组中的位置,要么不变,要么在原位置的基础上加上旧数组的长度。 - 不需要重新哈希,只需要判断
hash值的新增的最高位是0还是1即可,这大大提高了扩容的效率。
- 这里的一个巧妙之处是:因为新数组的长度是旧数组的两倍,
Java 8 的重要优化:引入红黑树
在 Java 7 及之前,HashMap 处理冲突的方式是纯链表,当某个桶中的链表过长时,查找效率会下降到 O(n)。
为了解决这个问题,Java 8 引入了 红黑树:
- 触发条件:当桶中链表的长度 超过 8 (
TREEIFY_THRESHOLD) 并且数组总长度 超过 64 时,链表会转换为红黑树。 - 优势:红黑树是一种自平衡的二叉查找树,其增、删、改、查的时间复杂度都是 O(log n),这极大地提高了在哈希冲突严重情况下的性能。
- 退化条件:当进行扩容时,如果某个桶中的红黑树的节点数量 减少到 6 以下 (
UNTREEIFY_THRESHOLD),红黑树会退化回链表,以节省空间。
这个优化使得 HashMap 在各种数据分布下都能保持非常好的性能。
总结与特性
| 特性 | 描述 |
|---|---|
| 数据结构 | 数组 + 链表 + 红黑树 |
| 核心原理 | 通过哈希函数将 key 映射到数组的索引上,实现快速存取。 |
| 哈希冲突处理 | 链地址法,冲突的元素以链表或红黑树的形式组织在同一个桶中。 |
| 时间复杂度 | - 平均情况:O(1)- 最坏情况:如果所有 key 的哈希值都相同,会退化为链表,为 O(n),但在良好的哈希函数和扩容机制下,这种情况极少发生。 |
| 线程安全 | 非线程安全,如果在多线程环境下使用 HashMap,可能会导致数据不一致、死循环等问题,在多线程环境下,应使用 ConcurrentHashMap 或 Hashtable。 |
key 的要求 |
key 必须实现 hashCode() 和 equals() 方法,并且两个方法要遵循约定:a.equals(b) 为 true,则 a.hashCode() 必须等于 b.hashCode()。 |
null 键 |
允许存在 一个 null 键。null 键的哈希值被固定为 0,所以它总是存放在数组的第一个位置。 |
| 性能关键 | - 哈希函数的质量:决定了哈希冲突的概率。 - 加载因子:权衡了空间和时间成本,值越大,空间利用率越高,但冲突概率也越大。 |
希望这个详细的解释能帮助你彻底理解 HashMap 的工作原理!