- 解析一个数据文件:比如一个
.csv、.xlsx或其他格式的表格文件,并将其读入 Python 的数据结构中(如列表、字典、Pandas DataFrame 等)。 - 解析一个名为
datatable的第三方库:这是一个专门为高性能数据处理而设计的 Python 库,类似于 Pandas 但速度更快。
我会详细讲解这两种情况,并提供完整的代码示例。

(图片来源网络,侵删)
解析常见的数据表格文件 (CSV, Excel 等)
这是最常见的需求,Python 中有几个强大的库可以完成这个任务,Pandas 是最流行、最通用的选择。
方法 1:使用 Pandas (最推荐)
Pandas 提供了 read_csv() 和 read_excel() 等函数,可以非常方便地将各种表格文件读入其核心数据结构 DataFrame 中。
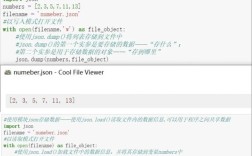
解析 CSV 文件
假设你有一个名为 data.csv 的文件,内容如下:
Name,Age,City Alice,25,New York Bob,30,Los Angeles Charlie,35,Chicago
代码示例:

(图片来源网络,侵删)
import pandas as pd
# 读取 CSV 文件
# pandas 会自动识别表头
df = pd.read_csv('data.csv')
# 打印 DataFrame 的前5行
print("前5行数据:")
print(df.head())
# --- 常用的解析和操作 ---
# 1. 查看数据基本信息
print("\n数据基本信息:")
print(df.info())
# 2. 查看数据的统计摘要
print("\n数据统计摘要:")
print(df.describe())
# 3. 访问特定列
print("\n'Name' 列:")
print(df['Name'])
# 4. 筛选数据 (年龄大于28的人)
print("\n年龄大于28的人:")
print(df[df['Age'] > 28])
# 5. 数据类型转换
# 假设 'Age' 列被读成了字符串,需要转换成整数
# df['Age'] = pd.to_numeric(df['Age'])
解析 Excel 文件 (.xlsx 或 .xls)
你需要先安装 openpyxl 或 xlrd 库来支持 Excel 文件。
pip install openpyxl
假设你有一个名为 data.xlsx 的 Excel 文件,内容与上面的 CSV 类似。
代码示例:
import pandas as pd
# 读取 Excel 文件
# 可以指定工作表的名称或索引 (sheet_name='Sheet1' 或 sheet_name=0)
df_excel = pd.read_excel('data.xlsx', sheet_name='Sheet1')
print("从Excel读取的数据:")
print(df_excel)
# 同样可以进行所有Pandas支持的操作
方法 2:使用 Python 内置库 (CSV 模块)
对于不需要复杂分析、只是简单读取 CSV 文件的情况,可以使用 Python 内置的 csv 模块,它更轻量级,但功能也相对基础。
代码示例:
import csv
# 读取 CSV 文件
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
# csv.reader 会将文件内容读成一个列表的列表
csv_reader = csv.reader(file)
# 读取表头
header = next(csv_reader)
print(f"表头: {header}")
# 逐行读取数据
data = []
for row in csv_reader:
# 将每一行数据转换成一个字典,键为表头
# 注意:这种方法假设所有行都有相同数量的列
data.append(dict(zip(header, row)))
print("\n解析后的数据 (列表 of 字典):")
for row in data:
print(row)
# --- 使用 csv.DictReader (更推荐的方式) ---
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
# csv.DictReader 直接将每一行解析为字典
dict_reader = csv.DictReader(file)
data_dict = []
for row in dict_reader:
data_dict.append(row)
print("\n使用 DictReader 解析后的数据:")
for row in data_dict:
print(row)
解析 datatable 库本身
datatable (也称为 Frame 或 dt) 是一个高性能的 Python 库,特别适合处理大型数据集(内存无法容纳的数据),它的语法和 Pandas 有些相似,但底层实现不同,速度极快。
你需要安装它:
pip install datatable
解析 CSV 文件
datatable 的核心是 dt.fread() 函数,它非常强大且快速。
代码示例:
import datatable as dt
# 使用 dt.fread() 读取 CSV 文件
# 它会自动推断数据类型、处理表头等
# 对于非常大的文件,这是首选方法
df_dt = dt.fread('data.csv')
# --- 常用的解析和操作 ---
# 1. 打印 Frame 的前5行
# dt 的 head() 方法返回一个新的 Frame
print("前5行数据:")
print(df_dt.head())
# 2. 查看 Frame 的基本信息
# .nrows, .ncols, .ltypes 分别是行数、列数和数据类型列表
print(f"\n行数: {df_dt.nrows}, 列数: {df_dt.ncols}")
print(f"列名: {df_dt.names}")
print(f"数据类型: {df_dt.ltypes}")
# 3. 转换为 Pandas DataFrame (如果需要使用Pandas生态)
# df_pandas = df_dt.to_pandas()
# print(df_pandas)
# 4. 转换为 NumPy 数组
# df_numpy = df_dt.to_numpy()
# print(df_numpy)
# 5. 选择列
print("\n'Name' 和 'City' 列:")
print(df_dt[:, ['Name', 'City']])
# 6. 筛选数据 (使用布尔表达式)
# 语法是 Frame[行筛选条件, 列选择]
print("\n年龄大于28的人:")
print(df_dt[df_dt[:, 'Age'] > 28, :])
# 7. 分组统计
# 计算每个城市的平均年龄
print("\n各城市平均年龄:")
print(df_dt[:, dt.mean(dt.f.Age), dt.f.City])
总结与对比
| 特性 | Pandas | Python 内置 csv |
datatable |
|---|---|---|---|
| 主要用途 | 通用数据分析、数据清洗、统计建模 | 简单的CSV读写、无需额外依赖 | 超大数据集的快速加载和处理 |
| 核心数据结构 | DataFrame |
列表、字典 | Frame |
| 易用性 | 非常高,API丰富,文档完善 | 简单,功能有限 | 较高,API与Pandas相似但不完全相同 |
| 性能 | 良好,但对超大文件内存要求高 | 较慢 | 极快,内存效率高,支持多线程 |
| 安装 | pip install pandas |
无需安装 (Python内置) | pip install datatable |
| 何时使用 | 绝大多数数据分析任务的首选。 | 快速脚本、轻量级处理、不想引入依赖时。 | 处理GB级别甚至更大的数据文件,性能是首要考虑因素时。 |
如何选择?
- 如果你是初学者或进行常规数据分析:直接学习并使用 Pandas,它是行业标准,社区支持强大,几乎能满足所有需求。
- 如果你只是想快速读取一个简单的CSV文件,不想安装任何库:使用 Python 内置的
csv模块。 - 如果你的数据文件非常大(比如超过内存容量),或者你对处理速度有极致要求:尝试使用
datatable,它可能会给你带来惊喜。