Java byte转int:从“坑”到“通”,一篇讲透所有转换方式与最佳实践
** 在Java开发中,将byte类型转换为int类型看似简单,实则暗藏玄机,本文将从基础概念出发,深入剖析Java类型转换的底层机制,详解5种主流转换方法,揭示符号扩展的“陷阱”,并提供跨语言通信、位运算等场景下的最佳实践,助你彻底掌握Java byte to int,写出健壮、高效的代码。

引言:为什么“byte转int”是Java开发者必经的“坎”?
“Java byte to int”,一个看似基础的问题,却是无数Java开发者在处理网络编程、文件I/O、嵌入式开发或与硬件交互时绕不开的“坎”,你可能遇到过这样的困惑:为什么一个明明是正数的byte值,转换成int后却变成了一个负数?
如果你也曾被这个问题困扰,或者想系统性地巩固Java基础知识,那么本文将为你拨开迷雾,让你从“知其然”到“知其所以然”。
基础篇:揭开byte与int的面纱
在深入转换之前,我们先快速回顾一下这两个基本数据类型。
- byte: 8位有符号整数,取值范围是 -128 到 127,它在内存中占用1个字节。
- int: 32位有符号整数,取值范围是 -2,147,483,648 到 2,147,483,647,它在内存中占用4个字节。
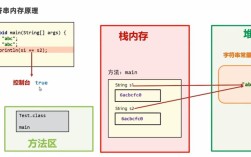
核心矛盾点在于:byte是8位的,而int是32位的,从byte转换到int,本质上是一个“窄类型”到“宽类型”的转换,Java编译器需要决定如何填充这多出来的24位。

核心篇:Java的“隐式”与“显式”转换
Java提供了多种方式来实现byte到int的转换,但它们的底层行为和适用场景截然不同。
隐式类型转换(自动类型提升)
这是最常见、最“自然”的方式,当你在表达式中使用一个byte类型,并且其需要被提升为int时,Java会自动完成转换。
代码示例:
public class ImplicitConversion {
public static void main(String[] args) {
byte b = 100;
// 在算术运算中,byte b会被自动提升为int
int result = b * 2;
System.out.println("原始byte值: " + b); // 输出: 100
System.out.println("转换后int值: " + result); // 输出: 200
}
}
工作原理:
在这个例子中,b * 2 这个表达式需要先计算,为了进行计算,Java虚拟机(JVM)会将b(一个byte)的值“符号扩展”(Sign-Extended)成一个32位的int值,因为100是正数,其最高位(符号位)是0,所以扩展后的前24位也都是0。100转换后依然是100。

适用场景: 当你需要进行数学运算,或者将byte值作为int类型的方法参数传递时,这是最推荐、最简洁的方式。
强制类型转换(显式转换)
当你明确地告诉编译器“我知道我要做什么”时,可以使用强制类型转换,但请注意,这通常用于int转byte,而不是byte转int,我们依然可以讨论它在byte转int场景下的“无意义”性。
代码示例:
public class ExplicitConversion {
public static void main(String[] args) {
byte b = 100;
// (int) b 是完全合法的,但实际上是多余的,因为编译器会自动处理
int result = (int) b;
System.out.println("原始byte值: " + b); // 输出: 100
System.out.println("转换后int值: " + result); // 输出: 100
}
}
工作原理:
在byte -> int的场景下,(int) b的写法是合法的,但它和隐式转换的效果完全一样,编译器会自动完成符号扩展。在byte转int时,显式转换是多余的,不推荐使用。
真正的用途:
强制类型转换的真正威力在于int -> byte,它会直接截断int的低8位,可能会丢失数据。
使用 Byte 包装类的 .intValue() 方法
这是面向对象风格的转换方式,适用于当你已经拥有一个Byte对象,而不是一个原始byte类型时。
代码示例:
public class WrapperConversion {
public static void main(String[] args) {
Byte bObj = new Byte("100"); // 或者 Byte bObj = 100; (自动装箱)
// 调用包装类的 intValue() 方法
int result = bObj.intValue();
System.out.println("原始Byte对象: " + bObj); // 输出: 100
System.out.println("转换后int值: " + result); // 输出: 100
}
}
工作原理:
Byte是byte的包装类,.intValue()方法的设计目的就是将包装对象中的值以int形式返回,其内部实现同样遵循Java的类型提升规则,进行符号扩展。
适用场景:
当你处理的是Byte对象(例如从集合中获取,或通过反射获得)时,这是最标准、最清晰的转换方式。
位掩码法(解决符号扩展的“坑”)
我们来直面文章开头提出的问题,为什么byte b = -1;转换成int后还是-1?因为Java的符号扩展机制。
问题重现:
byte b = -1; // 在内存中,byte的8位是: 1111 1111 int i = b; // JVM将b扩展为32位int,由于是负数,高位补1,得到: 1111 1111 1111 1111 1111 1111 1111 1111 System.out.println(i); // 输出: -1
这在网络协议中是个大问题!一个协议规定某个字段是1个字节的无符号整数(0-255),值为255(二进制1111 1111),如果用Java的byte接收,它会被解释为-1,直接转换成int得到-1,而不是期望的255。
解决方案:位掩码
我们可以使用位掩码 0xFF (二进制 1111 1111) 来“屏蔽”掉符号扩展带来的高24位1。
代码示例:
public class BitMaskConversion {
public static void main(String[] args) {
// 场景:一个字节的值,本意是无符号数 255
byte b = (byte) 0xFF; // 强制转换,b的值为 -1
// 错误的方式:得到 -1
int wrongResult = b;
System.out.println("错误转换结果: " + wrongResult); // 输出: -1
// 正确的方式:使用位掩码 0xFF
int correctResult = b & 0xFF;
System.out.println("正确转换结果: " + correctResult); // 输出: 255
}
}
工作原理:
b & 0xFF 的按位与操作会这样进行:
b(扩展为int后):1111 1111 1111 1111 1111 1111 1111 11110xFF:0000 0000 0000 0000 0000 0000 1111 1111- 按位与结果:
0000 0000 0000 0000 0000 0000 1111 1111(即十进制的255)
适用场景: 这是处理无符号字节到int转换的黄金标准,在网络编程、解析二进制文件、与硬件设备通信等场景中,必须使用此方法来确保数据的正确性。
使用 ByteBuffer
在进行NIO(New I/O)操作时,如果你有一个ByteBuffer,可以直接使用它的get()方法以int形式读取数据。
代码示例:
import java.nio.ByteBuffer;
public class ByteBufferConversion {
public static void main(String[] args) {
byte b = 100;
// 创建一个ByteBuffer,并放入byte值
ByteBuffer buffer = ByteBuffer.allocate(4);
buffer.put(b);
// 切换读模式
buffer.flip();
// 以int形式读取,ByteBuffer会正确处理符号扩展
int result = buffer.get(); // 注意:这里读取的是当前位置的byte并转换为int
System.out.println("从ByteBuffer转换的int值: " + result); // 输出: 100
}
}
工作原理:
ByteBuffer的get()方法在读取byte并将其作为int返回时,其内部实现遵循Java的类型提升规则,如果你需要处理字节数组,ByteBuffer提供了一种更强大、更灵活的方式来转换和操作多字节数据。
适用场景: NIO编程、处理二进制数据流、需要高效地进行字节与基本类型转换的场景。
总结与最佳实践
| 方法 | 代码示例 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 隐式转换 | int i = b; |
数学运算、常规参数传递 | 简洁、自动、符合直觉 | 无法处理无符号字节 |
| 强制转换 | int i = (int) b; |
不适用于byte->int |
(无) | 多余,可读性差 |
| 包装类方法 | int i = bObj.intValue(); |
处理Byte对象 |
面向对象,清晰 | 需要先有包装对象 |
| 位掩码法 | int i = b & 0xFF; |
处理无符号字节 | 准确、可靠 | 需要理解位运算 |
| ByteBuffer | int i = buffer.get(); |
NIO、二进制数据处理 | 功能强大、灵活 | 相对复杂,仅适用于NIO |
核心决策指南:
-
如果你只是在做普通的数学计算或方法调用,并且确定你的byte是有符号的:
- 直接使用隐式转换:
int i = myByte;,这是最简单、最符合Java语言习惯的方式。
- 直接使用隐式转换:
-
如果你正在处理网络协议、文件格式或硬件数据,并且一个byte代表的是0-255的无符号整数:
- 必须使用位掩码法:
int i = myByte & 0xFF;,这是避免数据错误的唯一可靠方法。
- 必须使用位掩码法:
-
如果你的代码中处理的是
Byte对象,而不是原始byte:- 使用包装类的
.intValue()方法:int i = myByteObj.intValue();,这能体现你的代码意图更清晰。
- 使用包装类的
-
如果你在进行复杂的NIO操作:
- 优先考虑使用
ByteBuffer,它能为你处理很多底层的转换和字节序问题。
- 优先考虑使用
通过本文的深度解析,相信你已经对Java中的byte to int转换有了全面而深刻的理解,选择正确的方法不仅关乎代码的正确性,更体现了你对Java语言底层机制的掌握程度,去写出更健壮、更专业的Java代码吧!